由于业务需要,我们需要将已有的 c++ 代码编译为 webassembly( wasm ),本文记录下编译过程中碰到的一些问题和解决方式。 能编译成 wasm 的语言有很多种,官网列举了一些目前支持编译到 wasm 的语言列表

其中 C/C++ 和 Rust 和 C# 是比较成熟的,其工具链比较成熟,rust 转 wasm 的实践可参考 zhuanlan.zhihu.com/p/38661879, 由于我们现有的项目是 c++,因此本文专注于 C++ 编译为 wasm 的实践。
项目简介
本项目是一个类似 RN|Weex 的一个跨端项目,其上层 DSL 为小程序,通过编译工具 (node cli) 将小程序编写的代码编译 (encode) 为一段 binary 代码(其包含了首屏的 vdom 和 style 信息以及业务的 js 代码),并将其动态下发给客户端,客户端将下发的 binary 代码进行 decode,并进行 native 渲染,并与业务的 js 代码进行动态绑定。
由于 encode 和 decode 存在大量的代码复用(内嵌了一个 mini 的 js 引擎实现),所以 encode 和 decode 的代码均通过 c++ 编写,客户端(ios|android)SDK 源码依赖 c++ 代码,而 node cli 则是需要先将 C++ 代码编译为动态库(linux 为 so,mac 下为 dylib,windows 下为 dll),然后 node 层通过 ffi(github.com/node-ffi/no…) 进行跨语言调用动态库代码。 虽然通过 ffi 我们能够成功的实现在 node 层调用 c++ 的代码,这仍然面临着一些问题
-
早期使用的 node-ffi 存在 node 的版本限制,不支持 node12 以上的版本(后来切换到 ref-napi 解决兼容性问题)
-
c++ 代码的 crash 会导致 node 进程奔溃,影响 node 在服务端侧的使用和稳定性
-
多平台的发布问题,如果我们想自己发布的 node cli 能够在多个平台正常运行基本上有两种方式
-
通过 node-gyp 交给用户侧完成 so 的编译过程,但是由于 c++ 代码里对标准库和语言版本都有一些要求,在用户侧编译对用户的环境有一定的要求
-
发布 cli 的时候,完成各个平台的动态库编译,这就要求每次发布 cli 的时候都要现在三个平台完成动态库的编译,这实际上要求我们在三个系统上搭建好自己的 gitlab-runner,然而公司的内部的 gitlab-runner 默认只支持 linux,这就要求我们自己搭建好一套成熟的 gitlab 多平台的 CICD 流程,这并不简单,而且这也难以解决开发者自己在本地发版的需求
-
动态库虽然能完美的支持 node、android 和 ios,但是在 web 端却无法去加载执行动态库,这阻止了我们将编译流程迁移到 web 的尝试。
-
虽然我们发布了动态库,使得用户无需自己本地编译动态库,动态库的调用仍然依赖于 ref-napi 这个库去完成 c++ 到 js 的 binding,该库需要在用户本地进行编译(依赖了 node-gyp 进而依赖了 xcode), 而 wasm 不依赖 xcode 等 c++ 环境,避免了用户对 c++ 编译环境的依赖。
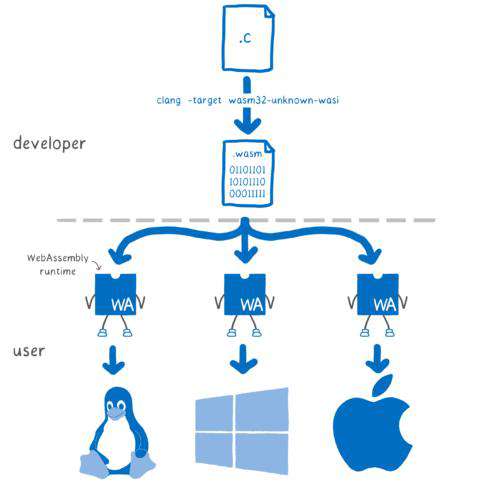
出于上述的一些限制,我们尝试将 c++ 代码编译为 wasm,wasm 除了其出色的执行性能,其还具有出色的跨平台特性,完美的契合了我们的需求。
- wasm 是与操作系统和 node 版本无关的,因此我们一次编译,即可运行在 linux|mac|window 等多个操作系统上,再也不需要为各个系统分别编译动态库产物, 在 node 8 以上即支持了 wasm,也无需担心 node 版本的兼容问题。
-
wasm 也可同时运行在 web,使得我们后期可以探索 web 上的编译方案。
-
wasm 的运行在一个沙盒环境中,并不会因为其执行异常导致进程奔溃。
因此我们尝试将该 c++ 模块变异的动态库迁移到 wasm。
wasm 的编译和运行流程
考虑如下的简单的 c 程序
// hello.c
#include
int main(){
printf("hello world\n");
return 0;
}
编译为可执行文件并执行
$ clang hello.c -o hello
$ ./hello
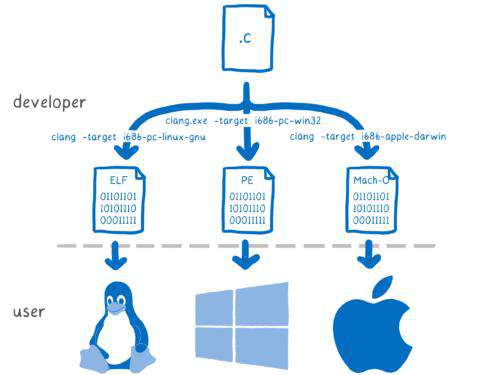
很不幸上述编译的代码只能运行在同样的 os 且同样的 cpu 指令集上。在 32 位 linux 编译出来的结果,无法运行在 64 位 linux 上,更无法运行在 mac 和 window 上。
我们将其编译为 wasm 碰到的第一个问题就是如何处理系统调用,实际上述编译结果难以跨平台的一大原因就在于不同操作系统的系统调用实现是不同的,我们必须要为不同的操作系统生成不同的代码来适配不同的系统调用实现。 这时候一个自然的处理方式就是将上述的系统调用结果编译到一个已经支持跨平台的 runtime 的系统调用上。幸运的是已经存在了多种上述的 runtime
-
browser
-
nodejs
-
wasi
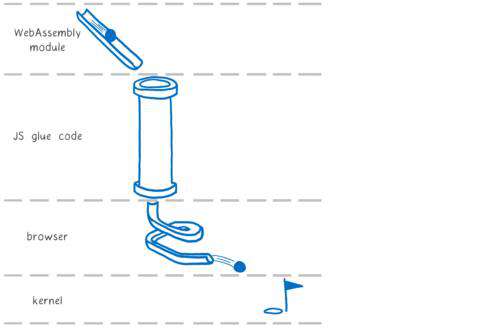
以浏览器为例,浏览器里 js 的 console.log 是一个天然的跨平台的系统调用,其可以平稳的运行在不同的操作系统上。 因此我们只需要将上述 c++ 代码编译为 wasm+ js glue 代码即可,js glue 代码负责将系统调用适配到浏览器提供的 js api 上。其流程如下图所示
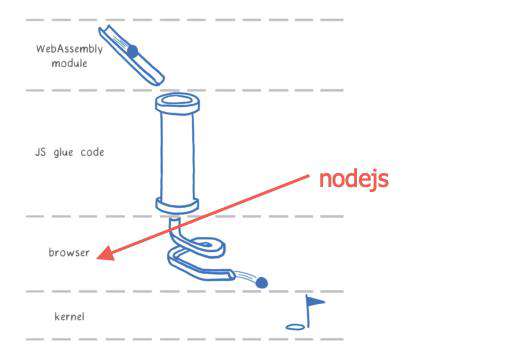
对于 nodejs 其处理方式和 browser 类似, 只是这时候 js glue code 适配的并非浏览器提供的 api,而是 node 提供的 api。 我们可以看下 emscripten 如何将上述代码编译上述结果
$ emcc hello.c -o hello.js $ node hello.js hello world
浏览器中也可以正常执行
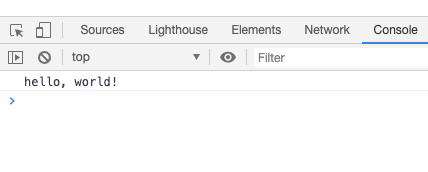
上述的使用方式都有一个缺点,因为生成的 wasm 依赖了 js gule 代码注入的 api,导致其依赖了 js glue 代码才能执行对应的 wasm。 这导致了如果其他的第三方环境如果想要脱离 js gule 代码使用生成的 wasm,则需要模拟 js glue code 给 wasm 注入的 api,然而 js glue 代码注入的 api 并非标准,也经常发生变化,这实际上导致生成的 wasm 很难在其他的环境下平稳运行。
标准化的 WASI
为了解决上述问题,wasm 制定了标准的 api 接口 (WASI),这时候 wasm 并不需要依赖 js glue 代码才能正常运行,任何实现了 WASI 的接口的 runtime 都能够正常加载该 wasm。 其实 wasm 本质上和 js 是无关的,其可以完全运行在独立的沙箱环境里,通过 WASI 和系统 API 进行交互,这实际上促使了 wasm runtime 的发展,此时已经并不局限在可以将多种语言编译为 wasm,更进一步的我们可以用各种语言实现 wasm 的 runtime,wasm 此时可以运行在除了 browser 和 node 之外的其他 runtime 里,甚至可以被内嵌入移动端的 sdk 里。目前已经支持的 wasi 的 runtime 包括
-
wasmtime, Mozilla’s WebAssembly runtime
-
Lucet, Fastly’s WebAssembly runtime
-
a browser polyfill
-
node@14 在开启 --experimental-wasi-unstable-preview1 的情况下
emcc 目前已经支持了生成 wasi 格式的代码,我们这次将上述的 hello-world 代码编译为支持 wasi
$ emcc hello.c -o hello.js -s STANDALONE_WASM
此时生成的 wasm 并不依赖了生成的 js glue code,我们使用任何支持 wasi 的 runtime 都可以执行生成的 wasm。 我们使用 wasmtime 执行上述代码

我们也可以通过 node 的 wasi 功能,执行上述代码
const fs = require('fs');
const { WASI } = require('wasi');
const wasi = new WASI({ args: process.argv, env: process.env, });
const importObject = { wasi_snapshot_preview1: wasi.wasiImport };
(async () => {
const wasm = await WebAssembly.compile(fs.readFileSync('./hello.wasm'));
const instance = await WebAssembly.instantiate(wasm, importObject);
wasi.start(instance);
})();
执行结果如下

我们发现上述代码并不需要处理任何系统调用的绑定,这一切都得益于 wasi 的支持。
如果我们的代码并不是以 STANDALONE\_WASM 模式下编译的,我们使用 wasi 的 runtime 执行,实际上会报错


因为此时生成的 wasm 会依赖 js gulu 代码注入的 api。
迁移过程
构建流程
一个 c++ 到 wasm 的编译流程基本上如下图所示,是 c++ -> llvm bitcode -> wasm + js(glue) | standalone wasm
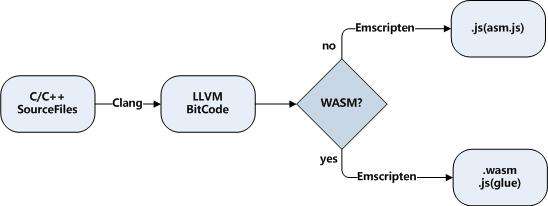
对于简单的 c++ 项目,我们可以直接调用 emcc 将 c++ 编译为 wasm,但是对于大型项目,都是使用 cmake 等构建工具进行构建的。 幸运的是 emscripten 很好的和 cmake 进行了集成,我们只需要进行如下替换
$ cmake => 替换为 emcmake cmake
$ make => 替换为 emmake make 即可
按照之前的 cmake 方式进行项目的构建。 此时 cmake 编译的产物是 llvm bit code , 我们可以接下来通过 emcc 将 llvm bit code 进一步编译为 wasm, 一个完整的编译步骤如下
cd build && emcmake ..
emmake make // 生成lib.a 的llvm bitcode
emcc lib.a -o lib.js // 生成 lib.wasm和lib.js
下面说一下编译中需要处理的细节问题。
保证函数导出
c++ name mangle
c++ 为了支持函数重载,默认会对函数的名称进行 mangle(即使没有重载) 与传统的将 c++ 编译成动态库,然后 js 通过 ffi 调用动态库导出的函数类似,emscripten 里如果需要在 JS 里使用 C++ 导出的函数,同样需要将 C++ 的函数进行导出。 c++ 为了支持重载函数,默认会对函数的名称进行 mangle 处理,这导致我们编写的函数和实际动态库导出的函数名不一致 如下代码为例
#include <stdio.h>
int myadd(int a,int b){
int res = a+b;
res = res + 2;
return res;
}
int main(){
int res = myadd(1,2);
printf("res: %d\n",res);
}
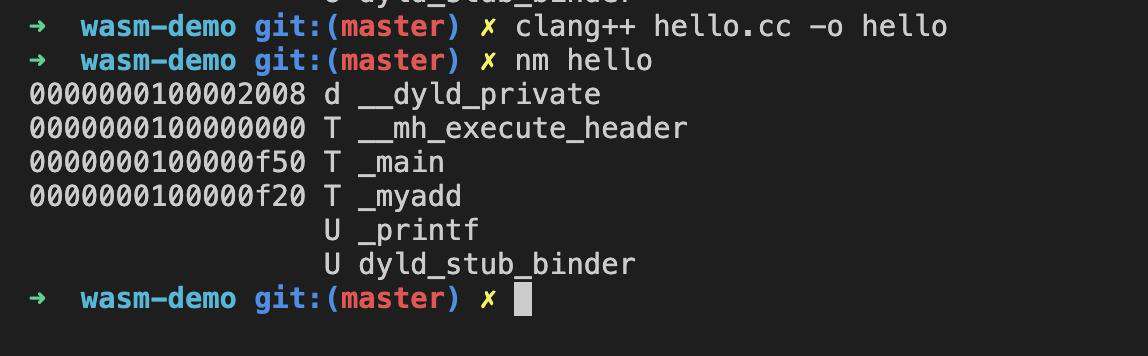
当我们使用 clang++ 进行编译后,再通过 nm 查看导出的 symbol 名
|
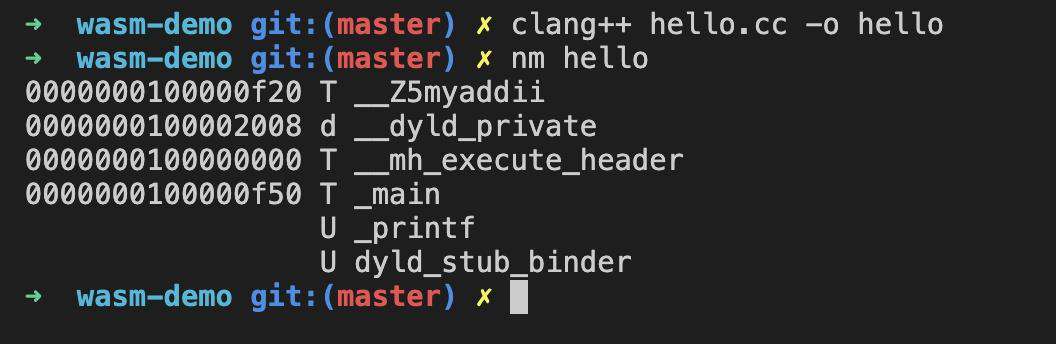
这时候原本的 myadd 函数名变成了__Z5myaddii,这对于 js 的使用方很不友好,因此我们需要关掉 c++ 的 name mangle 处理。 通过 extern "C" 我们可以阻止 c++ 的默认 name mangle 行为
#include <stdio.h>
extern "C" {
int myadd(int a,int b){
int res = a+b;
res = res + 2;
return res;
}
int main(){
int res = myadd(1,2);
printf("res: %d\n",res);
}
}
这样我们再次查看符号表,此时 myadd 变成了_myadd,这样 js 侧就可以通过_myadd 引用 myadd 函数了。
emcc 为了减小生成的 wasm 大小,对 c++ 的代码进行了各种优化,其中有些优化会导致我们无法在 js 里正常的读取 c++ 导出的函数,包括 DCE 和函数内联。
DCE
emscripten 为了保证生成的 wasm 尽可能小,会将很多没有使用的函数进行删除,既做了 Dead code ellimination(DCE,类似于 treeshaking) 为了保证需要使用的函数不被 emscripten 给 DCE 掉,需要告诉编译器不要删除该函数, emcc 通过 EXPORTED_FUNCTIONS来保证所需函数不被删除
emcc - s "EXPORTED_FUNCTIONS=['_main', '_my_func']" ...
emcc 的 EXPORTED_FUNCTIONS 的默认配置为 _main 因此我们看到我们的 main 没有被去除,实际上 main 和其他函数并没有本质区别 , 因此我们希望保留 main,则需要将 _main 也添加到EXPORTED_FUNCTIONS
函数内联
emscripten 为了减小运行时的函数开销,可能将部分函数内联 除了 DCE,函数内联也可能导致函数没有被正常导出, 为了保证函数不被内联,可以使用 EMSCRIPTEN_KEEPALIVE 来保证函数不被
inline void EMSCRIPTEN_KEEPALIVE yourCfunc() { .. }
C++ 与 Javascript 的互操作性
因为 Javascript 和 c++ 有完全不同的数据体系,Number 是两者的唯一交集,因此 JavaScript 与 C++ 相互调用的时候,都是通过 Number 类型进行交换。 当我们需要在 C++ 和 Javascript 传递其他类型时,需要先将其他类型转换成 Number 类型才可以进行交换。幸运的是 emscripten 为我们封装了一些功能函数来简化 C++ 和 Javascript 之间的参数传递。 我们可以通过 allocateUTF8 将一个 js 的 string 类型转换为 number 数组类型,同时可以通过 UTF8ToString 将 number 数组类型转换为 js 的 string 类型。 如下所示
const s1 = 'hello';
const s2 = 'world';
const res = Module._concat_str(Module.allocateUTF8(s1),Module.allocateUTF8(s2)); console.log('res:', Module.UTF8ToString(res)) // 'hello world'
emscripten 更进一步的我们封装了两个函数用于做参数类型转换,cwrap 和 ccall
这样上述代码即可简化为
const s1 = 'hello';
const s2 = 'world';
const res = Module.ccall('concat_string','string,['string','string'],[s1,s2])) console.log('res:',res);
如果函数需要多次调用,我们可以采用 cwrap 进行一次封装,可以多次调用
const concat = Module.cwrap('concat_string', 'string',['string','string']));
const r1 = concat(s1,s2); // 'hello world'
const r2 = concat(s2,s2); // 'world hello'
注意 emscripten 的这些内部函数默认是不导出的,如果要使用这些内部函数,需要编译时通过 EXTRA_EXPORTED_RUNTIME_METHODS将其导出
emcc -s \"EXTRA_EXPORTED_RUNTIME_METHODS=['cwrap','ccall']\" hello.c -o hello.js // 导出cwrap和ccall
模块化
emscripten 默认认为的执行环境是 browser,因此其导出的对象实际上是挂在全局的 Module 对象,且其加载是异步的,需要在 onRuntimeInitialized 事件回调中才能获取完整的导出模块,保证模块导出方法的正常运行。
浏览器
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Emscripten:Export1</title>
</head>
<body>
<script>
Module = {};
Module.onRuntimeInitialized = function() { //此时才能获得完整Module对象
console.log(Module._show_me_the_answer());
console.log(Module._add(12, 1.0));
}
</script>
<script src="export1.js"></script>
</body>
</html>
Nodejs 中
emscripten 还提供了另一种模块化的导出方式,其导出一个返回 promise 的函数
emcc -s MODULARIZE=1 hello.cc -o hello.js // 导出返回promise的函数
这样我们就很方便的使用 Module 了
const _loadWasm = require('./hello.js');
async main(){
const Module = await _loadWasm();
return Module._add(1,2);
}
文件系统处理
项目中的 C++ 里使用了很多系统的 API,主要是一些文件 IO,本来以为 wasm 没法支持文件 IO,但实际上 emscripten 对文件 IO 有很好的封装,emscripten 提供了一套虚拟文件系统,以兼容不同环境下文件 IO 的适配问题。
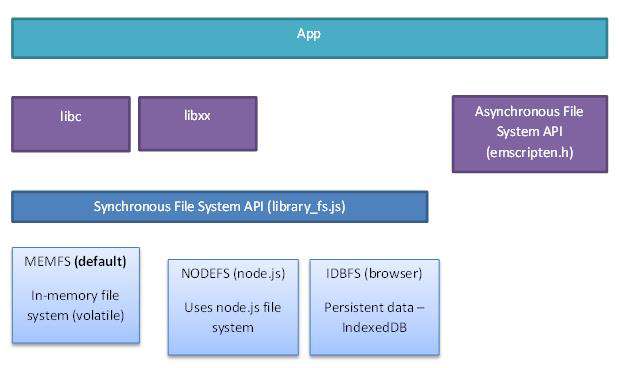
在最底层,Emscripten 提供了三套文件系统
-
MEMFS: 系统的数据完全存储在内存中,其非常类似于 webpack 的实现,在内存里模拟了一套文件系统的操作,运行时写入的文件不会持久化到本地
-
NODEFS: Node.js 文件系统,该系统可以访问本地文件系统,可以持久化存储文件,但只能用于 Node.js 环境
-
IDBFS: indexDB 文件系统,该系统基于浏览器的 IndexDB 对象,可以持久化存储,但只用于浏览器环境
我们最早尝试使用了 NODEFS 来处理,早期的 NODEFS 有个很大的限制,使用本地文件系统前需要先将需要操作的本地的文件夹进行挂载。
void setup_nodefs() {
EM_ASM(FS.mkdir('/data'); FS.mount(NODEFS, {root : '.'},'/data'); // 将当前文件夹挂载到/data目录下
);
}
int main() {
setup_nodefs(); // 先进行文件系统的挂载
FILE *fp = fopen("/data/nodefs_data.txt", "r+t"); // 访问当前文件下需要拼接上挂载前缀
if (fp == NULL)
fp = fopen("/data/nodefs_data.txt", "w+t");
int count = 0;
if (fp) {
fscanf(fp, "%d", &count);
count++;
fseek(fp, 0, SEEK_SET);
fprintf(fp, "%d", count);
fclose(fp);
printf("count:%d\n", count);
} else {
printf("fopen failed.\n");
}
return 0;
}
这种做法虽然可行,但是需要对我们原有的代码进行较大改动,emscripten 为了解决这个问题,提供了 NODERAWFS=1, 即在无需挂载文件系统的情况下,可以直接操作 NODEJS api,这样就避免对原有的代码进行改动
emcc -s NODERAWFS=1 hello.c -o hello.js
内存 OOM 处理
当我们将 c++ 转出 wasm 的时候,第一次运行的发现出现了较为严重的内存泄漏问题,经排查发现是由于 emscripten 默认生成的 js glue 代码会带上一些异常处理代码。

我们每次调用该 js gule 代码的时候,都会绑定一个事件,并且绑定的事件会捕获闭包上分配的 buffer, 导致累计捕获的 buffer 越来越多,导致内存泄漏。emscripten 也存在类似的 issue github.com/emscripten-…
很幸运的是 emscripten 也提供方式禁用该捕捉行为 github.com/emscripten-…
emcc build/liblepus.a -s NODEJS_CATCH_EXIT=0 -s NODEJS_CATCH_REJECTION=0 // 禁用nodejs的异常捕获
这样就避免了每次执行都会执行异常捕捉的绑定。 这样虽然避免了 uncaughtException 和 unhandleRejection 的重复绑定,但是仍然可能存在其他事件被重复绑定。因此我们需要保证 js glue 代码只执行一次
const _loadWasm = require('./js_glue.js') //
let task = null;
function loadWasm(){ // 保证在并发场景下_loadWasm也执行一次
if(!task){
task = _loadWasm();
}
return task;
}
export async function encode(){
const wasm = loadWasm();
return wasm.encode('src','dist');
}
emscripten 默认给 wasm 分配的内存是 16M,有时候这并不能满足需求,同样也可能造成 OOM, 有两种解决方式
-
通过
-s INITIAL_MEMORY=X调整为更大的内存 -
通过
-s ALLOW_MEMORY_GROWTH=1允许 wasm 动态增长所需内存
调试
wasm 调试
目前最新的 chrome 和 firefox 已经支持了 wasm 本身的调试
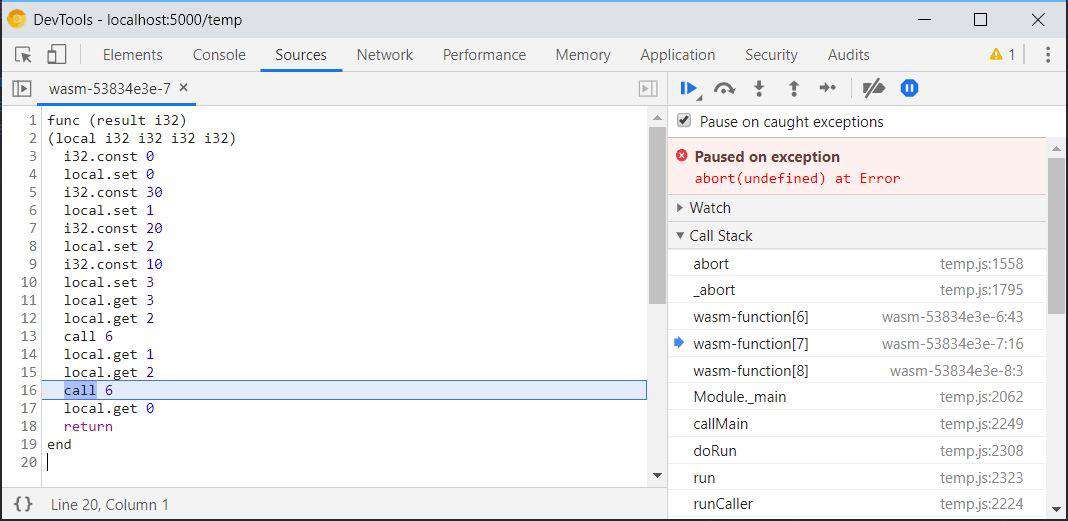
尽管我们可以在 wasm 上进行断点调试,但是对于复杂的应用,这种汇编级别的调试仍然难以满足我们的需求。我们更期望在源码层面上实现调试功能
sourcemap 调试
很幸运的是 emscripten 已经支持了 sourcemap 调试,这样在执行代码的时候,能定位到其相对的源码位置。
$ emcc -g4 hello.cc --source-map-base / -o index.html // g4开启sourcemap调试
我们可以看到如下图所示,我们成功的将断点断在了 c++ 源码的位置。
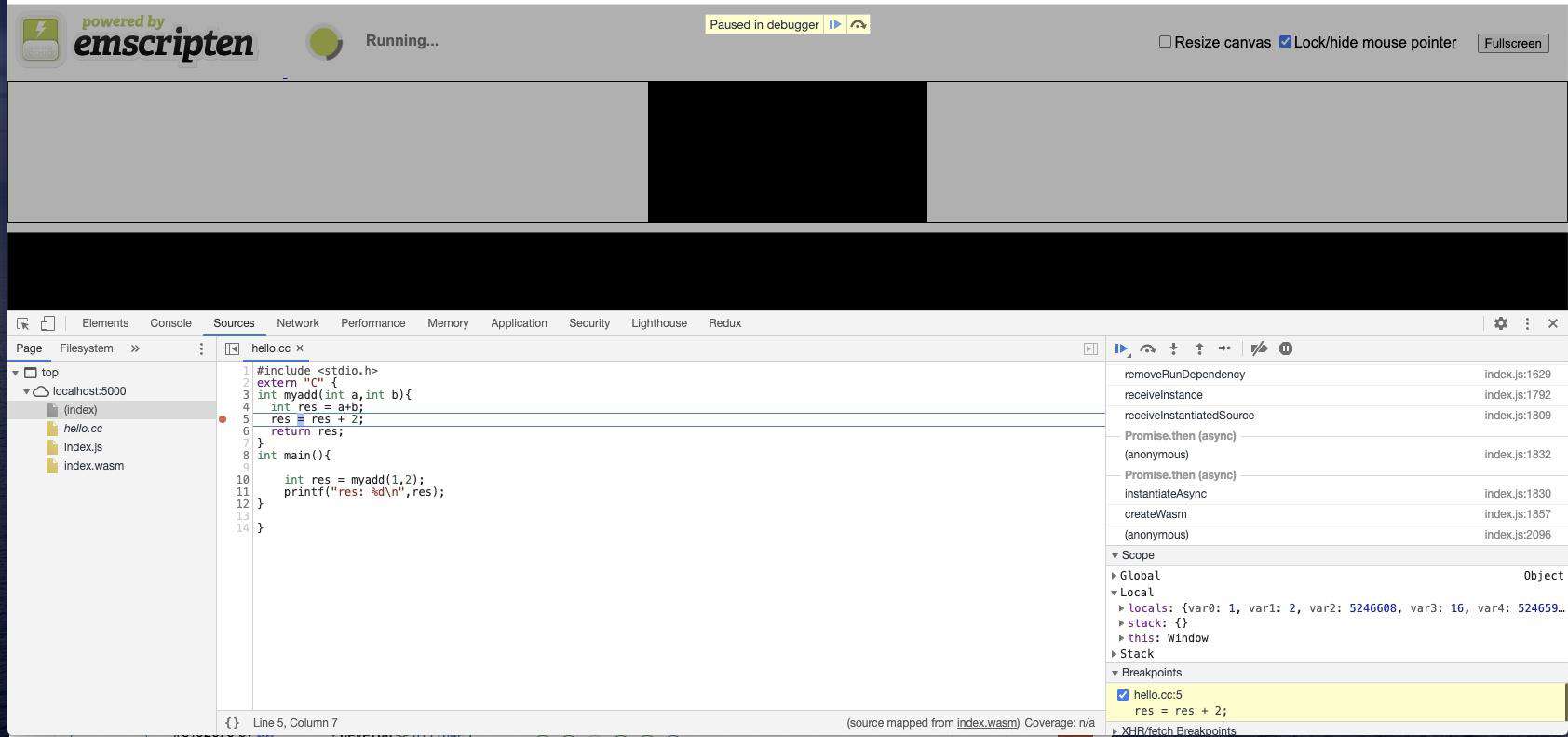
然而这种方式仍然存在一定的限制,我们看到 sourcemap 只处理了代码行数的映射关系,并没有处理 c++ 变量到 wasm 寄存器变量的映射关系,因此对于复杂的应用,sourcemap 调试仍然捉襟见肘。
dwarf 调试
除了 sourcemap 能处理源码和编译后的代码的映射关系外,dwarf 也是一种比较通用的调试数据格式 (debugging data format), 其广泛运用于 c|c++ 等 system programing language 上。其为调试提供了代码位置映射,变量名映射等功能。 emscripten 目前已经可以为生成的 wasm 代码带上 dwarf 信息。
$ emcc hello.cc -o hello.wasm -g // 带上dwarf信息 我们使用lldb和wasmtime进行调试
$ lldb -- wasmtime -g hello.wasm
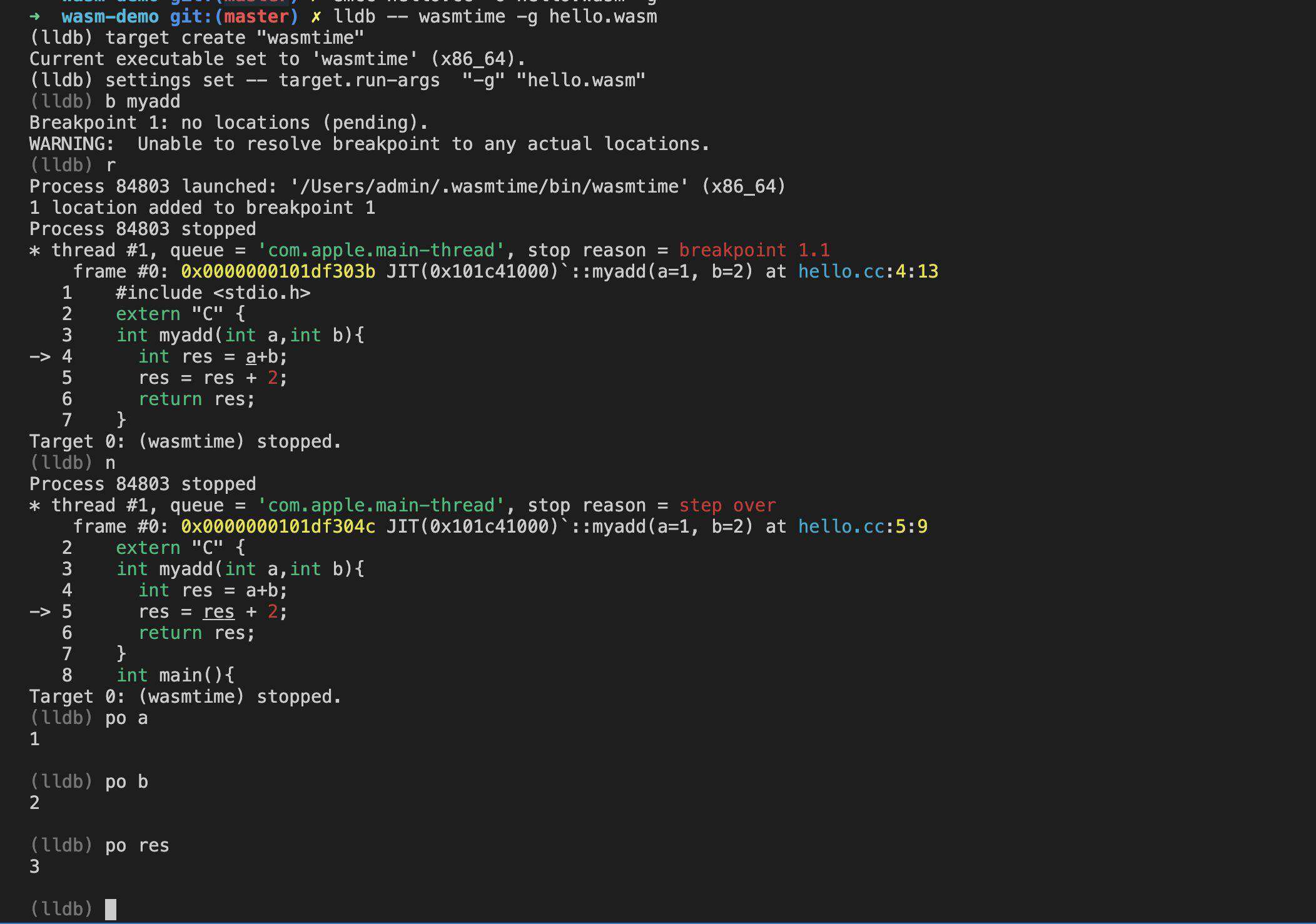
我们可以清楚的看出来 wasm 映射到 c++ 代码,并且变量也成功映射到 c++ 的变量里。
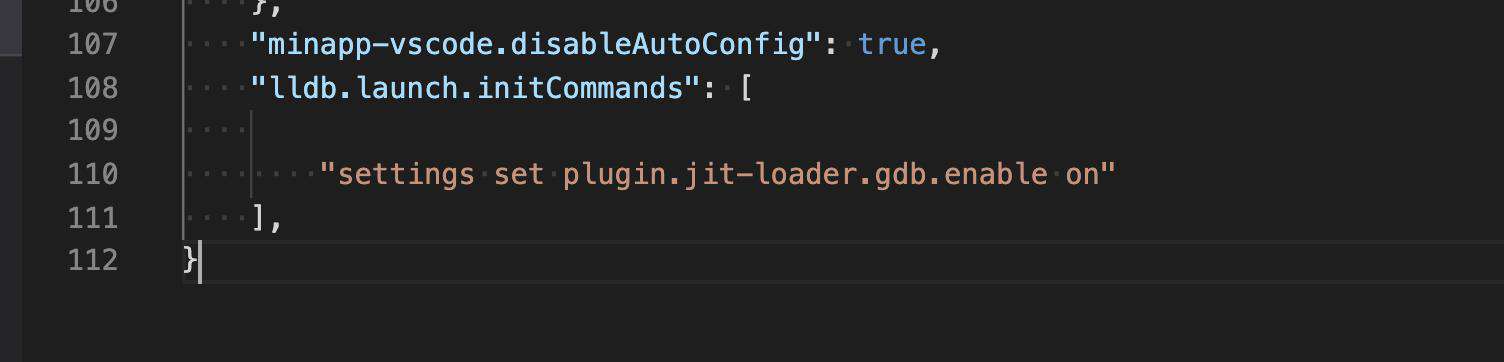
我们可以进一步的在 vscode 上依赖 codelldb 插件调试 wasm 程序,同样也需要进行 jit 的配置, 只需要在 settings.json 里配置 lldb 的 initCommands 即可
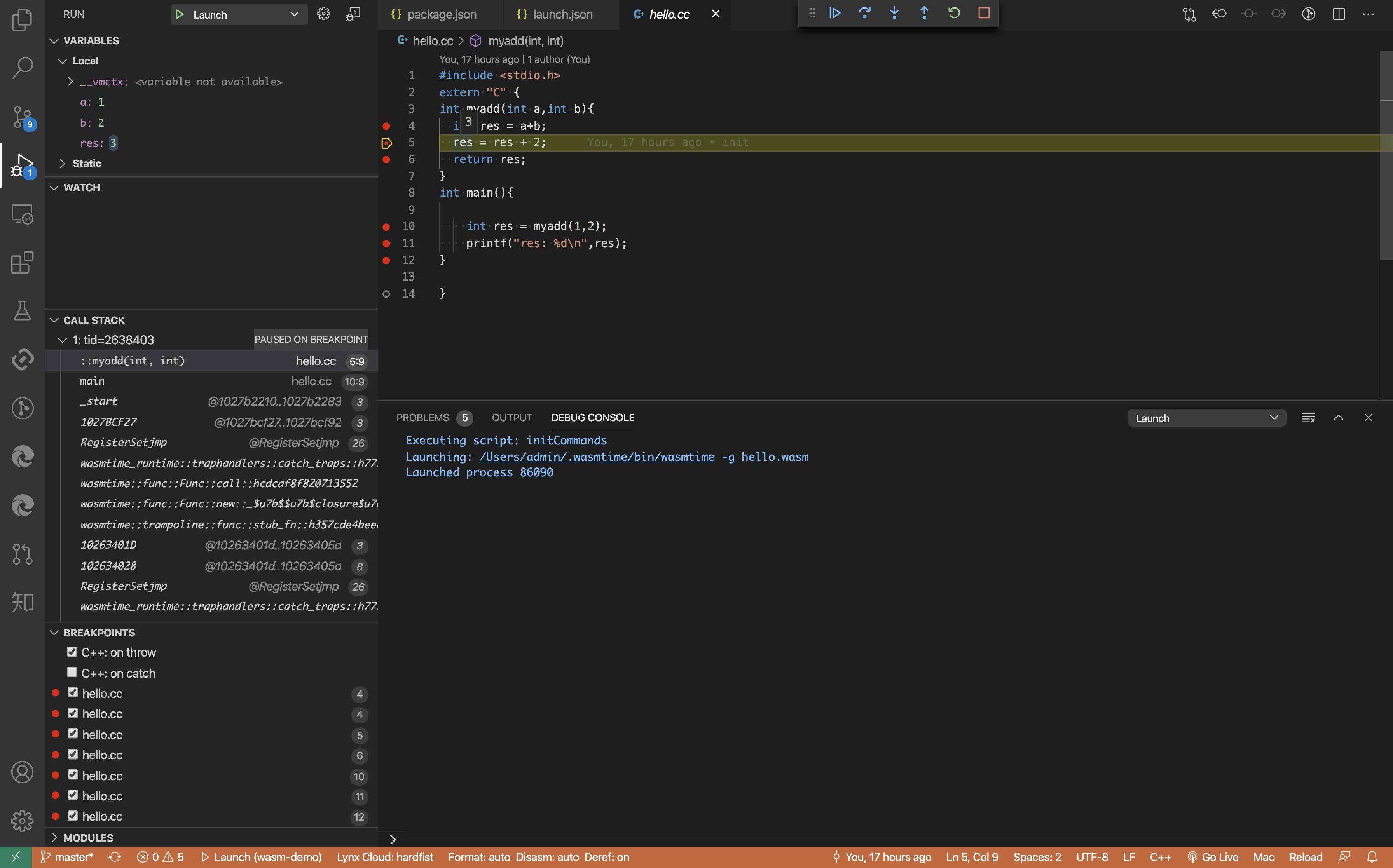
调试效果如下
我们虽然可以在通过 lldb 调试 wasm 应用,但是在浏览器上并没法执行 lldb,幸运的是浏览器已经开始尝试支持 wasm 的 dwarf 调试了, 最新的 chrome 可以开启 dwarf 调试功能的实验特性
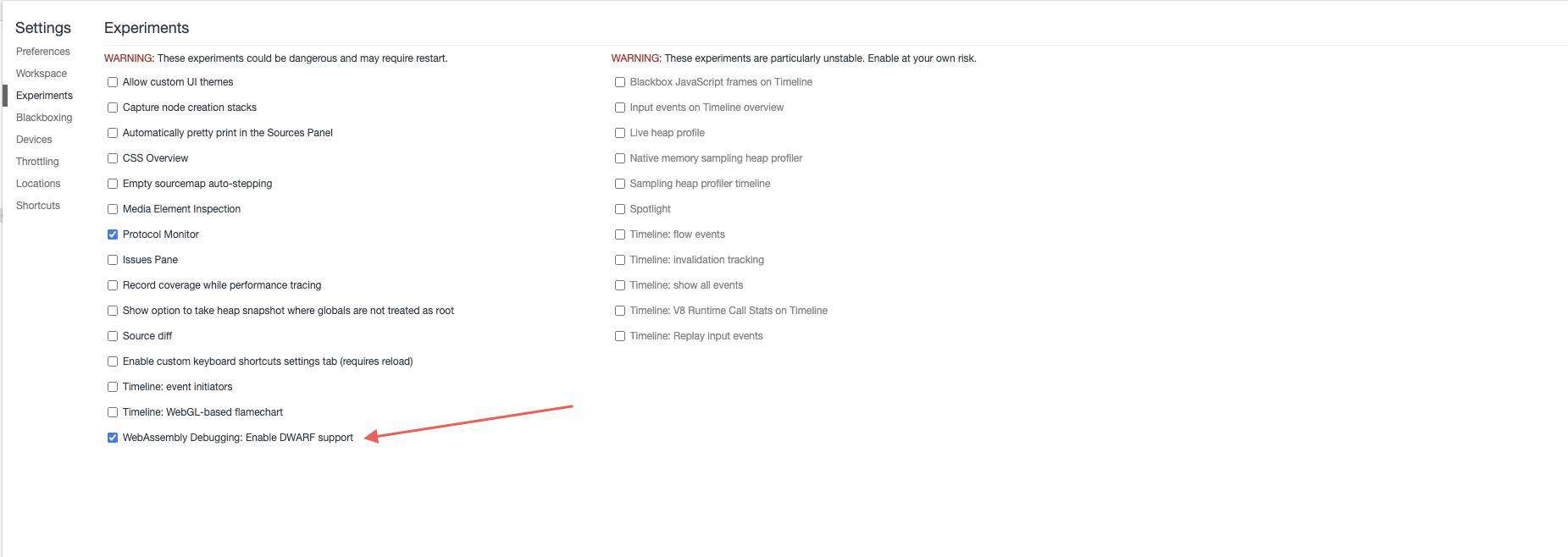
粗浅的试了下,貌似还是有 bug。。。并不能处理变量映射,显示的仍然是寄存器变量
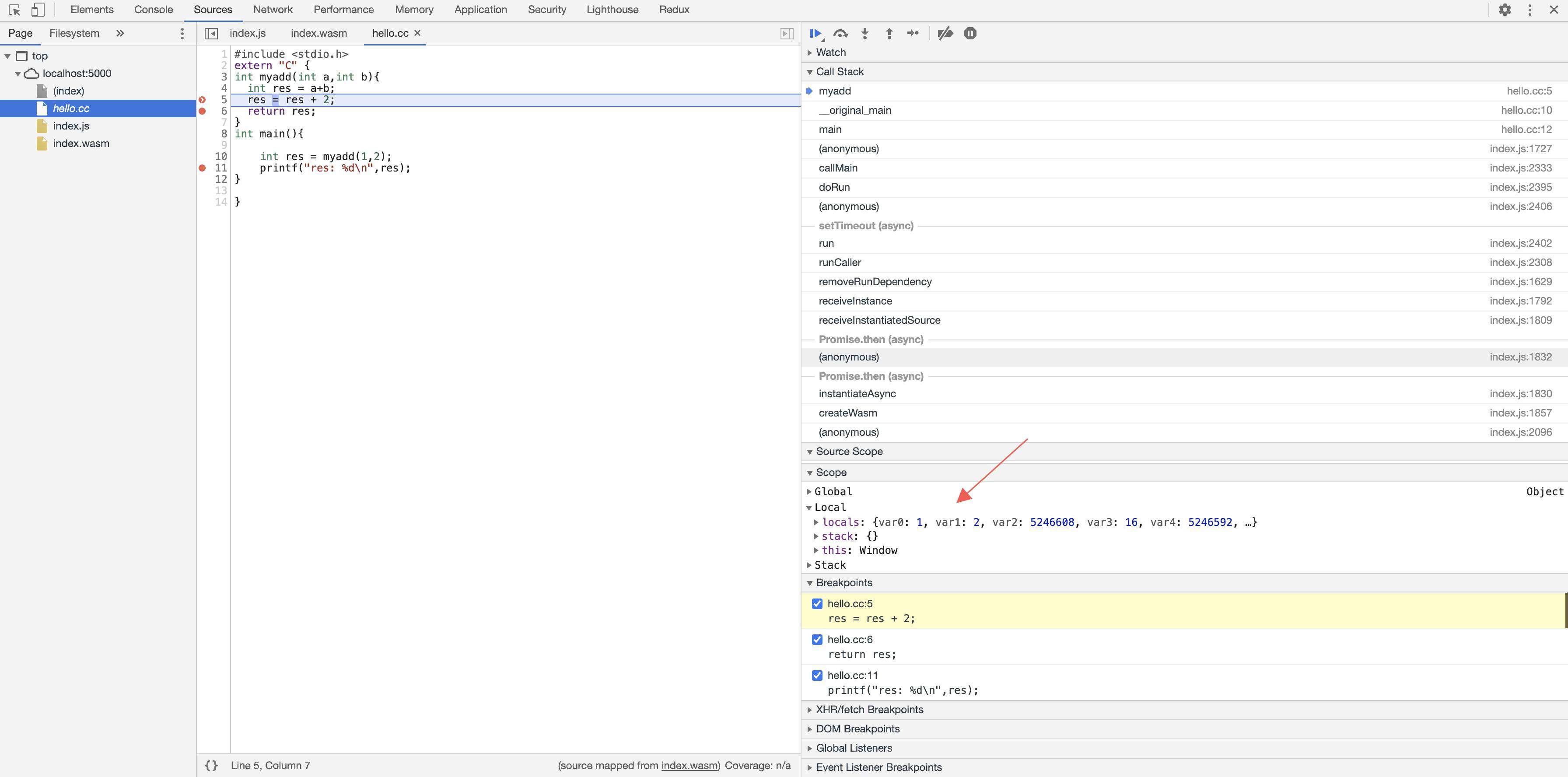
目前 node 对于 wasm 的 debug 支持程度貌似仍然有限,相关断点并未生效。
总结
实际的迁移过程比预想中的要简单很多,emscripten 的整个工具链非常完善,大部分的问题都有解决方案,实际上我们整个迁移过程,对 C++ 代码没有任何改动,只是一些编译工具的改动。这很大的扩展了前端的领域,我们的第三方库再也不局限于 npm,我们可以将众多的 C++ 库先编译为 wasm,从而为我所用。
参考资料
-
cliutils.gitlab.io/modern-cmak…
-
henryiii.github.io/cmake_works…
-
github.com/3dgen/cppwa…
-
hacks.mozilla.org/2019/09/deb…
-
hacks.mozilla.org/2019/03/sta…
-
emscripten.org/index.html
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!