函数式编程概念
一、什么是函数式编程
- 函数式编程(Functional Programming, FP),是一种编程风格,也可以认为是一种思维模式,和面向过程、面向对象是并列的关系。
- 函数式编程是对运算过程的抽象,函数指的并不是程序中的函数或者方法,而是数学中的函数映射关系,例如:y=cos(x),是y和x的关系。
- 在函数式编程中,相同的输入时必须得到相同的输出,也称为纯函数。
- 在函数式编程中,我们会将函数抽象为细粒度的函数,将这些函数组合为功能更强大的函数。
// 非函数式编程
let num1 = 2
let num2 = 3
let sum = num1 + num2
console.log(sum)
// 函数式编程
function add(n1, n2) {
return n1 + n2
}
let sum = add(2, 3)
console.log(sum)
二、为什么要学习函数式编程
- 函数式编程不依赖、不改变外界的状态,相同的输入必定返回相同的输出。因此,每个函数都是独立的,利于进行单元你测试和排错,以及函数的复用组合。
- 随着Vue,React的关注度提高,函数式编程也被更多人关注。生态也很不错,例如:lodash、Ramda等。
- 还有就是能读懂别人写的函数式代码啦~
函数式编程基础知识——函数
一、函数是一等公民
MDN传送门:MDN First-class Function
在JavaScript中”万物皆对象“,因此函数在JS中也是一个对象,我们可以把函数存储到变量或者数组中,函数也可以作为别的函数的参数和返回值,下面举例说明函数是一等公民的特性。
- 函数可以存储在变量或者数组中
//把函数复制给变量
let sayHi = function () {
console.log("hi")
}
- 函数可以作为参数传递
// 自定义forEach函数
// 遍历数组的每一项,并对每一项做出相应的处理
function forEach (array,fn) {
for(let item of array) {
fn(item)
}
}
// 测试
let arr = [1,2,3]
let func = function (value) {
value = value * 2
console.log(value)
}
forEach(arr,func) // 2 4 6
//也可以用下面的方式书写更简洁
forEach(arr,item => {
item = item * 2
console.log(item) // 2 4 6
})
- 函数作为返回值
// 函数作为返回值
function sayHi () {
let msg = 'hi'
return function () {
console.log(msg)
}
}
// 使用
const hi = sayHi() //返回的是函数function () {console.log(msg)}
//因此可以有两种调用方式
hi() // hi
sayHi()()//hi
二、高阶函数
高阶函数(Higher-order function)是什么?
- 函数作为参数
- 函数作为返回值
高阶函数的意义
// map函数:对数组中的每个元素遍历并处理,处理的结果放到一个新数组中返回
const map = (array, fn) => {
let results = []
for (const value of array) {
results.push(fn(value))
}
return results
}
// 使用
let arr = [1, 2, 3]
arr = map(arr, v => v * v)
console.log(arr) // 1 4 9
//如果我们想要返回这个数组加1的数组,不需要对map函数进行修改,只需要关注实现问题的函数即可
let arr1 = [1, 2, 3]
arr1 = map(arr1, v => v + 1)
console.log(arr1) // 2 3 4
常用的高阶函数
通用的特点:将函数作为参数
- forEach
- map
- filter
- some
- ......
三、闭包
闭包的概念
闭包(Closure):函数和其周围的状态(词法环境)的引用捆绑在一起形成闭包。
- 可以在领一个作用于中调用函数的内部函数并访问到该函数作用域中的成员。在上面函数作为返回值的过程中,我们已经用到了闭包。
// 正常情况下,执行完sayHi这个函数,里面的变量msg就会被释放掉
function sayHi () {
let msg = 'hi'
}
// 但是这种情况下,返回了一个函数,并且在返回的函数中还访问了原来函数内部的成员,就形成了闭包
function sayHi () {
let msg = 'hi'
return function () {
console.log(msg)
}
}
// hi()为外部函数,当外部函数对内部成员有引用的时候,那么内部的成员msg就不能被释放,当我们调用hi函数的时候就能访问到msg。
const hi = sayHi()
hi() // hi
// 注意
// 1.我们可以在另一个作用域调用sayHi的内部函数
// 2.当我们调用内部函数的时候我们可以访问到内部成员
闭包的核心作用
把函数内部成员的作用范围延长
闭包的本质
函数在执行的时候会放到一个执行栈上,当函数执行完毕之后会从执行栈上移除。但是堆上的作用域成员因为被外部引用不能释放,因此内部函数依然可以访问外部函数的成员。
/解读:函数执行的时候在执行栈上,执行完毕之后从执行栈上移除,内部成员的内存被释放。但是在函数执行完毕移除之后,释放内存的时候,如果外部有引用,则内部成员的内存不能被释放。/
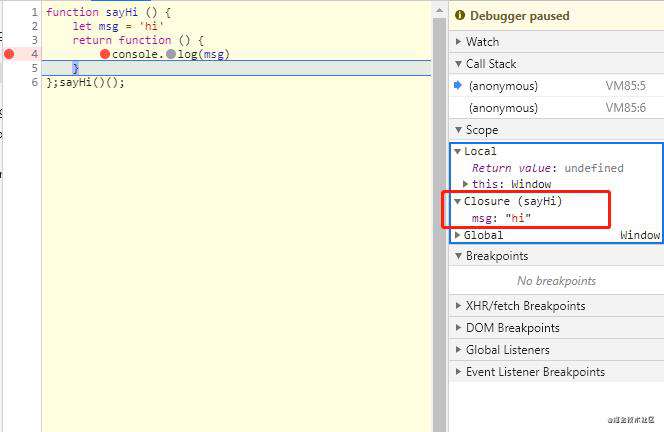
闭包的查看
可以使用Chrome调试工具进行断点调试查看闭包发生的时间和地点。
纯函数
纯函数概念
相同的输入永远会得到相同的输出,而且没有任何可观察的副作用。
纯函数就类似数学中的函数(用来描述输入和输出之间的关系),y = sin(x)。
- 函数式编程不会保留计算中间的结果,所以变量是不可变的(无状态的)
- 我们也可以把一个函数的执行结果交给另一个函数处理
let numbers = [1, 2, 3, 4, 5]
// 纯函数
// 对于相同的函数,输出是一样的
// slice方法,截取的时候返回截取的函数,不影响原数组
numbers.slice(0, 3) // => [1, 2, 3]
numbers.slice(0, 3) // => [1, 2, 3]
numbers.slice(0, 3) // => [1, 2, 3]
// 不纯的函数
// 对于相同的输入,输出是不一样的
// splice方法,返回原数组,改变原数组
numbers.splice(0, 3) // => [1, 2, 3]
numbers.splice(0, 3) // => [4, 5]
numbers.splice(0, 3) // => []
// 这也是一个纯函数
function getSum (n1, n2) {
return n1 + n2
}
console.log(getSum(1, 2)) // 3
console.log(getSum(1, 2)) // 3
console.log(getSum(1, 2)) // 3
Lodash——纯函数功能库
Lodash官网
Lodash中文文档
lodash 是一个纯函数的功能库,提供了模块化、高性能以及一些附加功能。提供了对数组、数字、对象、字符串、函数等操作的一些方法
使用Lodash
- 安装
npm init -y → npm i lodash
- 使用
const _ = require('lodash')
const array = ['jack', 'tom', 'lucy', 'kate']
// head的别名是first _.head(array)也可以
console.log(_.first(array)) //jack
console.log(_.last(array)) //kate
纯函数的好处
可缓存
因为对于相同的输入始终有相同的结果,那么可以把纯函数的结果缓存起来,可以提高性能。
const _ = require('lodash')
function getArea(r) {
console.log(r)
return Math.PI * r * r
}
let getAreaWithMemory = _.memoize(getArea)
console.log(getAreaWithMemory(4))
console.log(getAreaWithMemory(4))
console.log(getAreaWithMemory(4))
// 4
// 50.26548245743669
// 50.26548245743669
// 50.26548245743669
// 看到输出的4只执行了一次,因为其结果被缓存下来了
可测试
纯函数让测试更加的方便
并行处理
- 多线程环境下并行操作共享的内存数据很可能会出现意外情况。纯函数不需要访问共享的内存数据,所以在并行环境下可以任意运行纯函数
- 虽然JS是单线程,但是ES6以后有一个Web Worker,可以开启一个新线程
副作用
副作用就是让一个函数变得不纯,纯函数的根据市相同的输入返回相同的输出,如果函数依赖于外部的状态就无法保证输出相同,就会带来副作用,如下面的例子:
// 不纯的函数,因为它依赖于外部的变量mini,mini改变相同的输入就会得到不同的输出
let mini = 18
function checkAge (age) {
return age >= mini
}
// 纯函数,但是又硬编码,后续可以通过柯里化解决。
let mini = 18
function checkAge (age) {
return age >= mini
}
副作用来源:
- 配置文件
- 数据库
- 获取用户的输入
- ......
所有的外部交互都有可能带来副作用,副作用也使得方法通用性下降不适合扩展和可重用性,同时副作用会给程序带来安全隐患和不确定性,但是副作用不可能完全禁止,我们只能尽可能控制将它们控制在可控范围内发生。
柯里化(Currying)
我们先使用柯里化解决上一个案例中硬编码的问题
// 下面这段代码是解决了不纯的函数的问题,但是里面出现了硬编码
function checkAge (age) {
let mini = 18
return age >= mini
}
// 普通的纯函数
function checkAge (min, age) {
return age >= min
}
console.log(checkAge(18, 20)) //true
console.log(checkAge(18, 24)) //true
console.log(checkAge(20, 24)) //true
// 柯里化
// checkAge函数返回值为一个函数,在新函数中比较年龄与最小年龄。
function checkAge (min) {
return function (age) {
return age >= min
}
}
//ES6写法
let checkAge = min => (age => age >= min)
//使用checkAge返回18和20的函数
let checkAge18 = checkAge(18)
let checkAge20 = checkAge(20)
//使用返回的18、20函数接受年龄进行判断返回true or false
console.log(checkAge18(20)) //true
console.log(checkAge18(24)) //true
-
柯里化(Currying)
Lodash中的柯里化——curry()
_.curry(func)
- 功能:创建一个函数,该函数接收一个或多个 func的参数,如果 func 所需要的参数都被提供则执行 func 并返回执行的结果。否则继续返回该函数并等待接收剩余的参数。
- 参数:需要柯里化的函数
- 返回值:柯里化后的函数
const _ = require('lodash')
// 参数是一个的为一元函数,两个的是二元函数
// 柯里化可以把一个多元函数转化成一元函数
function getSum (a, b, c) {
return a + b + c
}
// 定义一个柯里化函数
const curried = _.curry(getSum)
// 如果输入了全部的参数,则立即返回结果
console.log(curried(1, 2, 3)) // 6
//如果传入了部分的参数,此时它会返回当前函数,并且等待接收getSum中的剩余参数
console.log(curried(1)(2, 3)) // 6
console.log(curried(1, 2)(3)) // 6
案例
我们平时判断字符串那种是否存在空白字符,或者提取字符串中的所有空白字符的时候可以使用字符串的match方法:''.match(/\s+/g),但是如果我们想要去除数组中的空白字符的时候,这个方法无法复用,下面我们用函数的方式来实现。
function match(reg, str) {
return str.match(reg)
}
//这样实现的话我们每次都需要传入两个参数,而且大多数时候reg正则表达式都是不变的,所以需要将这个函数柯里化
//柯里化处理
const _ = require('lodash')
//利用lodash的curry函数,第一个参数是匹配规则,第二个参数是字符串,生成一个match函数
const match = _.curry(function (reg, str) {
return str.match(reg)
})
// 根据规则haveSpace是一个匹配空格的函数
const haveSpace = match(/\s+/g)
console.log(haveSpace("hello world")) //[ ' ' ]
console.log(haveSpace("helloworld")) //null
// 可以判断字符串里面有没有空格
这样就实现了判断字符串里面是否有空格,现在我们又想实现字符串中是否有数字的话我们该怎么做呢?
// 根据规则haveNumber是一个匹配数字的函数
const haveNumber = match(/\d+/g)
console.log(haveNumber('abc')) // null
上面是针对字符串的,我们现在想要针对数组进行匹配
// 对于数组怎么匹配元素中有没有空格
const filter = _.curry(function(func, array) {
return array.filter(func)
})
// filter函数,第一个参数传递匹配元素中有没有空格
//第二个参数是指定的数组
console.log(filter(haveSpace, ['John Connor','John_Donne'])) // [ 'John Connor' ]
//如果觉得上面这样写法比较麻烦,可以在封装成一个函数
// filter可以传一个参数,然后返回一个函数
// 这个findSpace就是匹配数组元素中有没有空格的函数
const findSpace = filter(haveSpace)
console.log(findSpace(['John Connor','John_Donne'])) // [ 'John Connor' ]
案例思路总结
柯里化的好处就是我们可以最大程度的重用我们的函数。
const _ = require('lodash')
//match函数是根据一些正则,匹配字符串,返回匹配结果
const match = _.curry(function (reg, str) {
return str.match(reg)
})
//haveSpace函数是一个匹配空格的函数
const haveSpace = match(/\s+/g)
//haveNumber函数是一个匹配数字的函数
const haveNumber = match(/\d+/g)
//filter函数是定义一个数组和过滤规则,返回符合匹配规则的数组
const filter = _.curry(function(func, array) {
return array.filter(func)
})
//findSpace函数是匹配数组元素中有空格并返回符合情况的数组的函数
const findSpace = filter(haveSpace)
柯里化原理模拟
举个之前的例子
const _ = require('lodash')
function getSum (a, b, c) {
return a + b + c
}
const curried = _.curry(getSum)
console.log(curried(1, 2, 3)) // 6
console.log(curried(1)(2, 3)) // 6
console.log(curried(1, 2)(3)) // 6
实现一个柯里化转换函数的思路:
- 输入参数输出参数:调用传递一个纯函数的参数,完成之后返回一个柯里化函数
- 输入参数情况分析:
- 如果currid调用传递的参数和getSum函数参数个数相同,那么立即执行并返回调用结果
- 如果currid调用传递的参数是getSum函数的部分参数,那么就会返回一个新的函数,并且等待接收getSum的其他参数
- 我们需要重点关注获取调用的参数和判断实参和形参个数是否相同。
// 模拟柯里化函数
function curry (fun) {
//取名字是为了下面实参小于形参的时候进行调用
// args参数是数组的形式,需要用...展开
return function curryFn(...args) {
//判断实参和形参的个数是否相同
if(args.length < fun.length){
return function () {
// 在这里需要等待剩余参数的传递,如果剩余函数的参数个数加上之前的参数个数等于形参,那么就返回fun
// 第一部分参数在args里面,第二部分参数在arguments里面,要将两个合并并且展开
return curryfn(...args.concat(Arrary.from(arguments)))
}
}
// 实参的个数大于等于形参的个数
return fun(...args)
}
}
柯里化总结
- 柯里化可以让我们给一个函数传递较少的参数得到一个已经记住了某些固定参数的新函数(比如match函数新生成了haveSpace函数,里面使用了闭包,记住了我们给传递的正则表达式的参数)
- 这是一种对函数参数的'缓存'(使用了闭包)
- 让函数变的更灵活,让函数的粒度更小
- 可以把多元函数转换成一元函数,可以组合使用函数产生强大的功能
函数组合
-
纯函数和柯里化很容易写出洋葱代码
h(g(f(x)))-
获取数组的最后一个元素在转换成大写字母
_.toUpper(_.first(_.reverse(array)))
-
看看这些括号!是不是很像洋葱一层一层的。

我们为了避免代码变成洋葱代码,需要使用函数组合把细粒度的函数重新组合生成一个新的函数。
管道

如上图所示,表示程序中使用函数处理数据的过程,给fn函数输入参数a,返回结果b。可以将fn函数想象成一个管道,a数据通过管道fn,得到了b数据。
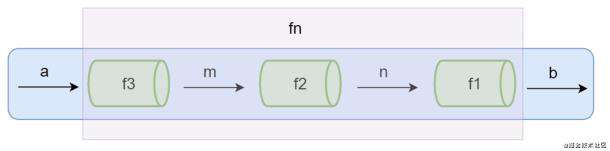
当fn函数比较复杂的时候,我们可以把函数fn拆分成多个小函数,此时多了个中间运算过程产生的m和n。如上图所示,我们可以把刚刚的fn函数管道拆分成了f1,f2,f3三个管道,数据a通过f3管道得到m,m在通过f2得到n,n再通过f1管道最终得到b数据。
函数组合概念
- 函数组合(compose):如果一个函数要经过多个函数处理才能得到最终值,这个时候可以把中间过程的函数合并成一个函数。
- 函数就像是数据的管道,函数组合就是把这些管道连接起来,让数据穿过多个管道形成最终结果
- 函数组合默认是从右向左执行
// 函数组合演示
function compose(f, g) {
return function (value) {
return f(g(value))
}
}
// 数组翻转函数
function reverse (array) {
return array.reverse()
}
// 获取函数第一个元素函数
function first (array) {
return array[0]
}
// 组合函数,获取函数最后一个元素
const last = compose(first, reverse)
console.log(last([1, 2, 3, 4])) // 4
但是这里我们只能实现两个函数的组合,如果有多个函数需要组合我们需要怎么做呢?请继续往下看。
Lodash中的组合函数
lodash 中组合函数 flow() 或者flowRight(),他们都可以组合多个函数。
- flow() 是从左到右运行
- flowRight() 是从右到左运行,使用的比较多
下面举个例子演示lodash中使用函数组合
const _ = require('lodash')
const reverse = arr => arr.reverse()
const first = arr => arr[0]
const toUpper = s => s.toUpperCase()
const f = _.flowRight(toUpper, first, reverse)
console.log(f(['one', 'two', 'three'])) // THREE
flowRight()原理模拟
我们先来分析一下flowRight()函数:
- 传入的参数个数不确定,并且都是函数,出参是一个函数,这个函数要有一个厨师的参数值
function compose (...args) {
//因为参数个数不确定所以用...
//args 为函数名的数组
return function (value) {
// reduce:对数组中的每个元素去执行我们提供的函数,并将其汇总为一个结果
// 因为默认从右向左执行所以需要reverse一下args数组
//acc默认值为value,fn就是args数组中的每个函数名
return args.reverse().reduce(function (acc,fn){
return fn(acc)
},value)
}
}
// 测试
const fTest = compose(toUpper, first, reverse)
console.log(fTest(['one', 'two', 'three'])) // THREE
//可以使用ES6的方式简化代码
const compose = (...args) => (value) =>
args.reverse().reduce((arr, fn) => fn(arr), value);
函数结合律
什么是函数结合律
我们把函数组合顺序颠倒对最终结果不会造成影响就是函数结合律。例如:
// 结合律(associativity)
let f = compose(f, g, h)
let associative = compose(compose(f, g), h) == compose(f, compose(g, h))
// true
const _ = require('lodash')
// 方式一
const f = _.flowRight(_.toUpper, _.first, _.reverse)
// 方式二
const f = _.flowRight(_.flowRight(_.toUpper, _.first), _.reverse)
// 方式三
const f = _.flowRight(_.toUpper, _.flowRight(_.first, _.reverse))
// 无论上面那种写法,下面都输出THREE这个相同的结果
console.log(f(['one', 'two', 'three'])) // THREE
函数组合的调试
在我们将多个函数组合的过程中,如果最终的结果和我们的预期不一致的话,我们该怎么调试去找到是哪一步出现的问题呢?我们怎么能知道中间每一步运行的结果呢?
直接上栗子
我们想要把NEVER SAY DIE转换成nerver-say-die打印出来,可以先将字符串按照空白字符拼成一个数组,再将大写转换为小写,最后将数组中的每一项用-拼起来。
const _ = require('lodash')
// 这里split函数需要传入两个参数,且我们最后调用的时候要传入字符串,所以字符串要在第二个位置传入,这里我们需要自己封装一个split函数
// _.split(string, separator)
// 将多个参数转成一个参数,用到函数的柯里化
const split = _.curry((sep, str) => _.split(str, sep))
// 大写变小写,用到toLower(),因为这个函数只有一个参数,所以可以在函数组合中直接使用
// 这里join方法也需要两个参数,第一个参数是数组,第二个参数是分隔符,数组也是最后的时候才传递,也需要交换
const join = _.curry((sep, array) => _.join(array, sep))
const f = _.flowRight(join('-'), _.toLower, split(' '))
console.log(f('NEVER SAY DIE')) //n-e-v-e-r-,-s-a-y-,-d-i-e
我们按照思路,但是最后打印发现实际输出和预期不一致,这时候我们该怎么调试呢?
// NEVER SAY DIE --> nerver-say-die
const _ = require('lodash')
const split = _.curry((sep, str) => _.split(str, sep))
const join = _.curry((sep, array) => _.join(array, sep))
// 我们需要对中间值进行打印,并且知道其位置,用柯里化输出一下
const log = _.curry((tag, v) => {
console.log(tag, v)
return v
})
// 从右往左在每个函数后面加一个log,并且传入tag的值,就可以知道每次结果输出的是什么
const f = _.flowRight(join('-'), log('after toLower:'), _.toLower, log('after split:'), split(' '))
// 从右到左
//第一个log:after split: [ 'NEVER', 'SAY', 'DIE' ] 正确
//第二个log: after toLower: never,say,die 转化成小写字母的时候,同时转成了字符串,这里出了问题
console.log(f('NEVER SAY DIE')) //n-e-v-e-r-,-s-a-y-,-d-i-e
// 修改方式,利用数组的map方法,遍历数组的每个元素让其变成小写
// 这里的map需要两个参数,第一个是数组,第二个是回调函数,需要柯里化
const map = _.curry((fn, array) => _.map(array, fn))
const f1 = _.flowRight(join('-'), map(_.toLower), split(' '))
console.log(f1('NEVER SAY DIE')) // never-say-die
Lodash的FP模块
在上面的例子中我们用到了split、join、map等函数都需要进行柯里化处理,将参数的顺序颠倒一下,对此Lodash提前为我们想到了,提供了FP模块。
- lodash的fp模块提供了很多对函数式编程友好的方法
- 提供了不可变的auto-curried iteratee-first data-last (函数优先,数据最后)的方法
// lodash 模块中
const _ = require('lodash')
// 数据置先,函数置后
_.map(['a', 'b', 'c'], _.toUpper)
// => ['A', 'B', 'C']
_.map(['a', 'b', 'c'])
// => ['a', 'b', 'c']
// 数据置先,规则置后
_.split('Hello World', ' ')
// lodash/fp 模块中
const fp = require('lodash/fp')
// 函数置先,数据置后
fp.map(fp.toUpper, ['a', 'b', 'c'])
fp.map(fp.toUpper)(['a', 'b', 'c'])
// 规则置先,数据置后
fp.split(' ', 'Hello World')
fp.split(' ')('Hello World')
Point Free
是一种编程风格,具体的实现是函数的组合,我们上面的例子用到的就是这种风格。
Point Free: 我们可以把数据处理的过程定义成与数据无关的合成运算,不需要用到代表数据的那个参数,只要把简单的运算步骤合成到一起,在使用这种模式之前我们需要定义一些辅助的基本运算函数。
- 不需要指明处理的数据
- 只需要合成运算过程
- 需要定义一些辅助的基本运算函数
// 非Point Free模式
// Hello World => hello_world
function f (word) {
return word.toLowerCase().replace(/\s+/g,'-')
}
// Point Free风格
const fp = require('lodash/fp')
const f = fp.flowRight(fp.replace(/\s+/g,'-'),fp.toLower)
console.log(f('Hello World'))
Functor(函子)
为什么要学习函子
函子(representative functor)是范畴论里的概念,指从任意范畴到集合范畴的一种特殊函子。 我们没有办法避免副作用,但是我们尽可能的将副作用控制在可控的范围内,我们可以通过函子去处理副作用,我们也可以通过函子去处理异常,异步操作等。
什么是函子?
- 容器:包含值和值的变形关系(这个变形关系就是函数)
- 函子:是一个特殊的容器,通过一个普通的对象来实现,该对象具有 map 方法,map方法可以运行一个函数对值进行处理(变形关系)
理解Functor
class Container {
// of静态方法,返回一个new Container,在外部创建对象的时候就可以省略new关键字
static of (value) {
return new Container(value)
}
constructor (value) {
// 这个函子的值是保存在内部的,不对外公布
// _下划线的成员都是私有成员,外部无法访问,值是初始化的传的参数
this._value = value
}
//有一个对外的方法map,接收一个函数,来处理这个值
map (fn) {
// 返回一个新的函子,把fn处理的值返回给函子,由新的函子来保存
return Container.of(fn(this._value))
}
}
// 创建一个函子的对象
let r = Container.of(5)
.map(x => x + 1) // 6
.map(x => x ** 2) // 36
// 返回了一个container函子对象,里面有值是36,不对外公布
console.log(r) //Container { _value: 36 }
总结
- 函数式编程的运算不直接操作值,而是由函子完成
- 函子就是一个实现了 map 契约的对象
- 我们可以把函子想象成一个盒子,这个盒子里封装了一个值
- 想要处理盒子中的值,我们需要给盒子的 map 方法传递一个处理值的函数(纯函数),由这个函数来对值进行处理
- 最终 map 方法返回一个包含新值的盒子(函子)
注意:在Functor中如果我们不小心传入了null或undefined,怎么办呢?
// 值不小心传入了空值或undefined(副作用)
Container.of(null)
.map(x=>x.toUpperCase()) // 报错,使得函数不纯
Maybe函子
- 我们在编程的过程中可能会遇到很多错误,我们需要对这些错误作出相应的处理
- MayBe 函子的作用就是可以对外部的空值情况做处理(控制副作用在允许的范围内)
class MayBe {
static of (value) {
return new MayBe(value)
}
constructor (value) {
this._value = value
}
map(fn) {
// 判断一下value的值是不是null和undefined,如果是就返回一个value为null的函子,如果不是就执行函数
return this.isNothing() ? MayBe.of(null) : MayBe.of(fn(this._value))
}
// 定义一个判断是不是null或者undefined的函数,返回true/false
isNothing() {
return this._value === null || this._value === undefined
}
}
const r = MayBe.of('hello world')
.map(x => x.toUpperCase())
console.log(r) //MayBe { _value: 'HELLO WORLD' }
// 如果输入的是null,是不会报错的
const rnull = MayBe.of(null)
.map(x => x.toUpperCase())
console.log(rnull) //MayBe { _value: null }
我们用Maybe函子来将外部的值为null或undefined的问题解决,但是如果我们对这个函子进行多次map调用,最后返回的是null,我们并不知道是在哪一步中返回的,要想解决这个问题需要看下个Either函子。
MayBe.of('hello world')
.map(x => x.toUpperCase())
.map(x => null)
.map(x => x.split(' '))
// => Maybe
Either函子
- Either 两者中的任何一个,类似于 if...else...的处理
- 当出现问题的时候,Either函子会给出提示的有效信息,
- 异常会让函数变的不纯,Either 函子可以用来做异常处理
// 因为是二选一,所以要定义left和right两个函子
class Left {
static of (value) {
return new Left(value)
}
constructor (value) {
this._value = value
}
map (fn) {
return this
}
}
class Right {
static of (value) {
return new Right(value)
}
constructor (value) {
this._value = value
}
map (fn) {
return Right.of(fn(this._value))
}
}
let r1 = Right.of(12).map(x => x + 2)
let r2 = Left.of(12).map(x => x + 2)
console.log(r1) // Right { _value: 14 }
console.log(r2) // Left { _value: 12 }
// 为什么结果会不一样?因为Left返回的是当前对象,并没有使用fn函数
// 那么这里如何处理异常呢?
// 我们定义一个字符串转换成对象的函数
function parseJSON(str) {
// 对于可能出错的环节使用try-catch
// 正常情况使用Right函子
try{
return Right.of(JSON.parse(str))
}catch (e) {
// 错误之后使用Left函子,并返回错误信息
return Left.of({ error: e.message })
}
}
let rE = parseJSON('{name:xm}')
console.log(rE) // Left { _value: { error: 'Unexpected token n in JSON at position 1' } }
let rR = parseJSON('{"name":"xm"}')
console.log(rR) // Right { _value: { name: 'xm' } }
console.log(rR.map(x => x.name.toUpperCase())) // Right { _value: 'XM' }
IO函子
- IO就是输入输出,IO 函子中的 _value 是一个函数,这里是把函数作为值来处理
- IO 函子可以把不纯的动作存储到 _value 中,延迟执行这个不纯的操作(惰性执行),包装当前的操作
- 把不纯的操作交给调用者来处理
const fp = require('lodash/fp')
class IO {
// of方法快速创建IO,要一个值返回一个函数,将来需要值的时候再调用函数
static of(value) {
return new IO(() => value)
}
// 传入的是一个函数
constructor (fn) {
this._value = fn
}
map(fn) {
// 这里用的是new一个新的构造函数,是为了把当前_value的函数和map传入的fn进行组合成新的函数
return new IO(fp.flowRight(fn, this._value))
}
}
// test
// node执行环境可以传一个process对象(进程)
// 调用of的时候把当前取值的过程包装到函数里面,再在需要的时候再获取process
const r = IO.of(process)
// map需要传入一个函数,函数需要接收一个参数,这个参数就是of中传递的参数process
// 返回一下process中的execPath属性即当前node进程的执行路径
.map(p => p.execPath)
console.log(r) // IO { _value: [Function] }
// 上面只是组合函数,如果需要调用就执行下面
console.log(r._value()) // C:\Program Files\nodejs\node.exe
Task函子(异步执行)
- 函子可以控制副作用,还可以处理异步任务,为了避免地狱之门
- 我们使用 folktale 中的 Task 来演示,代替异步任务
- folktale 一个标准的函数式编程库。和 lodash、ramda 不同的是,他没有提供很多功能函数。只提供了一些函数式处理的操作,例如:compose、curry 等,一些函子 Task、Either、 MayBe 等
folktale的安装
首先安装folktale的库
npm i folktale
folktale中的curry函数
const { compose, curry } = require('folktale/core/lambda')
// curry中的第一个参数是函数有几个参数,为了避免一些错误
const f = curry(2, (x, y) => x + y)
console.log(f(1, 2)) // 3
console.log(f(1)(2)) // 3
folktale中的compose函数
const { compose, curry } = require('folktale/core/lambda')
const { toUpper, first } = require('lodash/fp')
// compose 组合函数在lodash里面是flowRight
const r = compose(toUpper, first)
console.log(r(['one', 'two'])) // ONE
Task函子异步执行
- folktale(2.3.2) 2.x 中的 Task 和 1.0 中的 Task 区别很大,1.0 中的用法更接近我们现在演示的
函子
- 这里以 2.3.2 来演示
const { task } = require('folktale/concurrency/task')
const fs = require('fs')
// 2.0中是一个函数,函数返回一个函子对象
// 1.0中是一个类
//读取文件
function readFile (filename) {
// task传递一个函数,参数是resolver
// resolver里面有两个参数,一个是reject失败的时候执行的,一个是resolve成功的时候执行的
return task(resolver => {
//node中读取文件,第一个参数是路径,第二个是编码,第三个是回调,错误在先
fs.readFile(filename, 'utf-8', (err, data) => {
if(err) resolver.reject(err)
resolver.resolve(data)
})
})
}
//演示一下调用
// readFile调用返回的是Task函子,调用要用run方法
readFile('package.json')
.run()
// 现在没有对resolve进行处理,可以使用task的listen去监听获取的结果
// listen传一个对象,onRejected是监听错误结果,onResolved是监听正确结果
.listen({
onRejected: (err) => {
console.log(err)
},
onResolved: (value) => {
console.log(value)
}
})
/** {
"name": "Functor",
"version": "1.0.0",
"description": "",
"main": "either.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"folktale": "^2.3.2",
"lodash": "^4.17.20"
}
}
*/
案例
在package.json文件中提取一下version字段
const { task } = require('folktale/concurrency/task')
const fs = require('fs')
const { split, find } = require('lodash/fp')
// 2.0中是一个函数,函数返回一个函子对象
// 1.0中是一个类
//读取文件
function readFile (filename) {
// task传递一个函数,参数是resolver
// resolver里面有两个参数,一个是reject失败的时候执行的,一个是resolve成功的时候执行的
return task(resolver => {
//node中读取文件,第一个参数是路径,第二个是编码,第三个是回调,错误在先
fs.readFile(filename, 'utf-8', (err, data) => {
if(err) resolver.reject(err)
resolver.resolve(data)
})
})
}
//演示一下调用
// readFile调用返回的是Task函子,调用要用run方法
readFile('package.json')
//在run之前调用map方法,在map方法中会处理的拿到文件返回结果
// 在使用函子的时候就没有必要想的实现机制
.map(split('\n'))
.map(find(x => x.includes('version')))
.run()
// 现在没有对resolve进行处理,可以使用task的listen去监听获取的结果
// listen传一个对象,onRejected是监听错误结果,onResolved是监听正确结果
.listen({
onRejected: (err) => {
console.log(err)
},
onResolved: (value) => {
console.log(value) // "version": "1.0.0",
}
})
Pointed函子
- Pointed 函子是实现了 of 静态方法的函子of 方法是为了避免使用 new 来创建对象,更深层的含义是of 方法用来把值放到上下文
- Context(把值放到容器中,使用 map 来处理值)
class Container {
// Point函子
// 作用是把值放到一个新的函子里面返回,返回的函子就是一个上下文
static of (value) {
return new Container(value)
}
……
}
// 调用of的时候获得一个上下文,之后是在上下文中处理数据
Contanier.of(2)
.map(x => x + 5)
Monad函子(单子)
IO函子的嵌套问题
- 用来解决IO函子多层嵌套的一个问题
const fp = require('lodash/fp')
const fs = require('fs')
class IO {
static of (value) {
return new IO(() => {
return value
})
}
constructor (fn) {
this._value = fn
}
map(fn) {
return new IO(fp.flowRight(fn, this._value))
}
}
//读取文件函数
let readFile = (filename) => {
return new IO(() => {
//同步获取文件
return fs.readFileSync(filename, 'utf-8')
})
}
//打印函数
// x是上一步的IO函子
let print = (x) => {
return new IO(()=> {
console.log(x)
return x
})
}
// 组合函数,先读文件再打印
let cat = fp.flowRight(print, readFile)
// 调用
// 拿到的结果是嵌套的IO函子 IO(IO(x))
let r = cat('package.json')
console.log(r)
// IO { _value: [Function] }
console.log(cat('package.json')._value())
// IO { _value: [Function] }
// IO { _value: [Function] }
console.log(cat('package.json')._value()._value())
// IO { _value: [Function] }
/**
* {
"name": "Functor",
"version": "1.0.0",
"description": "",
"main": "either.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"folktale": "^2.3.2",
"lodash": "^4.17.20"
}
}
*/
上面遇到多个IO函子嵌套的时候,那么_value就会调用很多次,这样的调用体验很不好,所以我们需要进行优化。
什么是Monad函子
- Monad 函子是可以变扁的 Pointed 函子,用来解决IO函子嵌套问题,IO(IO(x))
- 一个函子如果具有 join 和 of 两个方法并遵守一些定律就是一个 Monad
实现一个Monad函子
我们主要要理解monad的实现原理。
const fp = require('lodash/fp')
const fs = require('fs')
class IO {
static of (value) {
return new IO(() => {
return value
})
}
constructor (fn) {
this._value = fn
}
map(fn) {
return new IO(fp.flowRight(fn, this._value))
}
join () {
return this._value()
}
// 同时调用map和join方法
flatMap (fn) {
return this.map(fn).join()
}
}
let readFile = (filename) => {
return new IO(() => {
return fs.readFileSync(filename, 'utf-8')
})
}
let print = (x) => {
return new IO(()=> {
console.log(x)
return x
})
}
let r = readFile('package.json')
.flatMap(print)
.join()
// 执行顺序
/**
* readFile读取了文件,然后返回了一个IO函子
* 调用flatMap是用readFile返回的IO函子调用的
* 并且传入了一个print函数参数
* 调用flatMap的时候,内部先调用map,当前的print和this._value进行合并,合并之后返回了一个新的函子
* (this._value就是readFile返回IO函子的函数:
* () => {
return fs.readFileSync(filename, 'utf-8')
}
* )
* flatMap中的map函数执行完,print函数返回的一个IO函子,里面包裹的还是一个IO函子
* 下面调用join函数,join函数就是调用返回的新函子内部的this._value()函数
* 这个this._value就是之前print和this._value的组合函数,调用之后返回的就是print的返回结果
* 所以flatMap执行完毕之后,返回的就是print函数返回的IO函子
* */
r = readFile('package.json')
// 处理数据,直接在读取文件之后,使用map进行处理即可
.map(fp.toUpper)
.flatMap(print)
.join()
// 读完文件之后想要处理数据,怎么办?
// 直接在读取文件之后调用map方法即可
/**
* {
"NAME": "FUNCTOR",
"VERSION": "1.0.0",
"DESCRIPTION": "",
"MAIN": "EITHER.JS",
"SCRIPTS": {
"TEST": "ECHO \"ERROR: NO TEST SPECIFIED\" && EXIT 1"
},
"KEYWORDS": [],
"AUTHOR": "",
"LICENSE": "ISC",
"DEPENDENCIES": {
"FOLKTALE": "^2.3.2",
"LODASH": "^4.17.20"
}
}
*/
Monad函子小结
什么是Monad?
具有静态的IO方法和join方法的函子
什么时候使用Monad?
- 当一个函数返回一个函子的时候,我们就要想到monad,monad可以帮我们解决函子嵌套的问题。
- 当我们想要返回一个函数,这个函数返回一个值,这个时候可以调用map 方法
- 当我们想要去合并一个函数,但是这个函数返回一个函子,这个时候我们要用flatMap 方法
附录
- 函数式编程指北
- 函数式编程入门
- Pointfree 编程风格指南
- 图解 Monad
- Functors, Applicatives, And Monads In Pictures
参考
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?


发表评论
还没有评论,快来抢沙发吧!