浏览器原理系列文章终于迎来终结篇-V8编译流水线,本文来聊聊我们写出的JS代码是如何编译和执行的,这是一段有趣的旅程,Let's go!
V8是什么?
V8 是一个谷歌开源的JavaScript引擎,内置在 Chrome 浏览器中,它将 JavaScript 语言编译成机器可以理解的语言并执行。目前市面上有很多 JavaScript 引擎,诸如 SpiderMonkey、JavaScriptCore 等。而 V8 是当下使用最广泛的 JavaScript 引擎,全球有超过 25 亿台安卓设备,而这些设备中都使用了 Chrome 浏览器,所以我们写的 JavaScript 应用,大都跑在 V8 上。
V8 能使用地如此广泛,拥有如此庞大的生态圈,和它许多革命性的设计是分不开的。
在 V8 出现之前,所有的 JavaScript 虚拟机采用的都是解释执行的方式,这是 JavaScript 执行速度过慢的一个主要原因。而 V8 率先引入了即时编译(JIT)的双轮驱动的设计,这是一种权衡策略,混合编译执行和解释执行这两种手段,给 JavaScript 的执行速度带来了极大的提升。另外,V8 也引入了惰性编译、内联缓存、隐藏类等机制,进一步优化了 JavaScript 代码的编译执行效率。对内联缓存和隐藏类感兴趣的同学可戳 浏览器原理系列-V8引擎对象存储的优化 查看~
运行时环境
当我们把一段JS代码丢给 V8 虚拟机时, V8 会先首先准备代码的运行时环境,这个环境包括堆空间和栈空间、全局执行上下文、全局作用域、内置的内建函数、宿主环境提供的扩展函数和对象、消息循环系统。
宿主环境
V8 引擎需要一个宿主环境才可以执行JS代码,这个宿主环境可以是浏览器、Node.js 进程,也可以是其他的定制开发环境。 浏览器为V8提供了基础的消息循环系统、全局变量、web API,V8只需提供ECMAScript定义的一些对象和核心函数,这包括了 Object、Function、String。 除此之外, V8 还提供了垃圾回收器、协程等基础内容,不过这些功能依然需要宿主环境的配合才能完整执行。 Node.js 也是 V8 的另外一种宿主环境,它提供了不同的宿主对象和宿主的 API,但是整个流程依然是相同的,比如 Node.js 也会提供一套消息循环系统,也会提供一个运行时的主线程。
堆空间和栈空间
栈空间主要是用来管理 JavaScript 函数调用的,栈是内存中连续的一块空间,同时栈结构是“先进后出”的策略。在函数调用过程中,涉及到上下文相关的内容都会存放在栈上,比如原生类型、引用到的对象的地址、函数的执行状态、this 值等都会存在在栈上。当一个函数执行结束,那么该函数的执行上下文便会被销毁掉。
栈空间的最大的特点是空间连续,所以在栈中每个元素的地址都是固定的,因此栈空间的查找效率非常高 。但是通常在内存中,很难分配到一块很大的连续空间,因此,V8 对栈空间的大小做了限制,如果函数调用层过深,那么 V8 就有可能抛出栈溢出的错误。
堆空间是一种树形的存储结构,用来存储对象类型的离散数据, JavaScript 中除了原生类型的数据,其他的都是对象类型,诸如函数、数组,在浏览器中还有 window 对象、document 对象等,这些都是存在堆空间的。宿主在启动 V8 的过程中,会同时创建堆空间和栈空间,再继续往下执行,产生的新数据都会存放在这两个空间中。
全局执行上下文和全局作用域
V8 初始化了基础的存储空间之后,接下来就需要初始化全局执行上下文和全局作用域了。当 V8 开始执行一段可执行代码时,会生成一个执行上下文。V8 用执行上下文来维护执行当前代码所需要的变量声明、this 指向等。
执行上下文中主要包含三部分,变量环境、词法环境和 this 关键字。 比如在浏览器的环境中,全局执行上下文中就包括了 window 对象,还有默认指向 window 的 this 关键字,另外还有一些 Web API 函数,诸如 setTimeout、XMLHttpRequest 等API。
全局执行上下文在 V8 的生存周期内是不会被销毁的,它会一直保存在堆中,这样当下次在需要使用函数或者全局变量时,就不需要重新创建了。
构造事件循环系统
接下来V8需要一个主线程,用来执行 JavaScript 和执行垃圾回收等工作,V8 是寄生在宿主环境中的,它并没有自己的主线程,而是使用宿主所提供的主线程,V8 所执行的代码都是在宿主的主线程上执行的。
如果只有一个主线程依然是不行的,因为线程执行完一段代码后就会自动退出,为了让线程在执行完代码之后继续运行,需要添加一个循环语句,在循环语句中监听下个事件,不断地获取新事件并执行,大意如下:
while(1){
Task task = GetNewTask();
RunTask(task);
}
如果主线程正在执行一个任务,这时候又来了一个新任务,比如 V8 正在操作 DOM,这时候浏览器的网络线程完成了一个页面下载的任务,而且 V8 注册监听下载完成的事件,那么这种情况下就需要引入一个消息队列,让下载完成的事件暂存到消息队列中,等当前的任务执行结束之后,再从消息队列中取出正在排队的任务。当执行完一个任务之后,我们的事件循环系统会重复这个过程,继续从消息队列中取出并执行下个任务。
生成字节码
V8准备好运行时环境后,会先对 JavaScript 代码进行解析 (Parser),并生成为 AST 和作用域信息,之后 AST 和作用域信息被输入到一个称为 Ignition 的解释器中,并将其转化为字节码 ,然后再根据情况解释执行字节码或者直接将字节码编译成二进制代码然后执行。
字节码
字节码是指在编译过程中产生的中间代码,可以把字节码看成是为机器代码的抽象 ,在V8中,字节码有两个作用:
-
第一个是解释器可以直接解释执行字节码 ;
-
第二个是优化编译器可以将字节码编译为二进制代码,然后再执行二进制机器代码。
虽然现在的架构使用了字节码,但在早期的 V8 中并没有字节码,那时候V8团队认为这个中间环节会牺牲代码的执行速度,于是采用了非常激进的策略,直接将JavaScript代码编译成机器代码,但这种模式在最新的V8引擎中已经被抛弃了。原因是什么呢?我们来看看。
代码缓存
当 JavaScript 代码在浏览器中被执行的时候,需要先被 V8 编译,早期的 V8 会将 JavaScript 编译成未经优化的二进制机器代码,然后再执行这些未优化的二进制代码,通常情况下,编译占用了很大一部分时间,几乎和执行所消耗的时间是差不多的。
怎么样可以节约编译时间呢?是否可以把编译后的二进制码保存下来,如果代码没有做任何改动,直接使用上次的编译结果呢?基于此 V8 引入了二进制代码缓存,通过把二进制代码保存在内存中来节约编译时间。
V8 使用两种代码缓存策略来缓存生成的代码:
-
首先,是 V8 第一次执行一段代码时,会编译源 JavaScript 代码,并将编译后的二进制代码缓存在内存中,我们把这种方式称为 内存缓存 (in-memory cache)。然后通过 JavaScript 源文件的字符串在内存中查找对应的编译后的二进制代码。这样当再次执行到这段代码时,V8 就可以直接去内存中查找是否编译过这段代码。如果内存缓存中存在这段代码所对应的二进制代码,那么就直接执行编译好的二进制代码。
-
其次,V8 除了采用将代码缓存在内存中策略之外,还会将代码缓存到硬盘上,这样即便关闭了浏览器,下次重新打开浏览器再次执行相同代码时,也可以直接重复使用编译好的二进制代码。
实践表明,在浏览器中采用了二进制代码缓存的方式,初始加载时分析和编译的时间缩短了 20%~40%。
但这个策略是一个很明显的“空间换时间”的策略,牺牲存储空间来换取执行速度,如果缓存的二级制码较多,会占用很大一部分内存。而且存储的是二进制码,其体积也是非常大的。
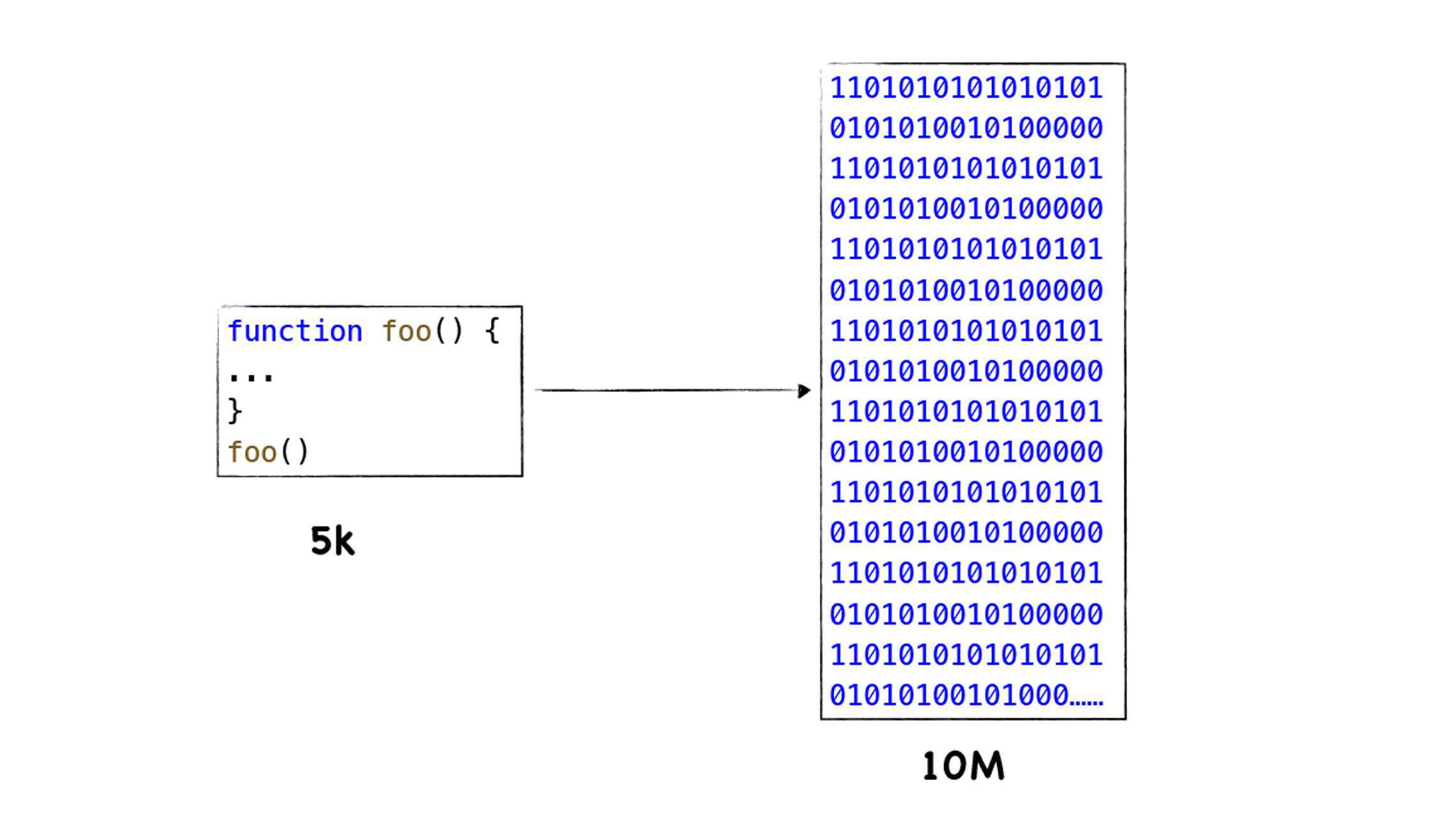
从上图我们可以看出, 二进制代码所占用的内存空间是 JavaScript 代码的几千倍 ,通常一个页面的 JavaScript 几 M 大小,转换为二进制代码就变成几十 M 了,如果是 PC 应用,多占用一些内存,也不会太影响性能,但是在移动设备流行起来之后,V8 过度占用内存的问题就充分暴露出来了。因为通常一部手机的内存不会太大,如果过度占用内存,那么会导致 Web 应用的速度大大降低。
为了解决内存占用的问题,V8团队提出了生成中间产物字节码,将字节码缓存起来,同样可以达到节约二次编译时间的目的,同时内存占用大小会大大降低。
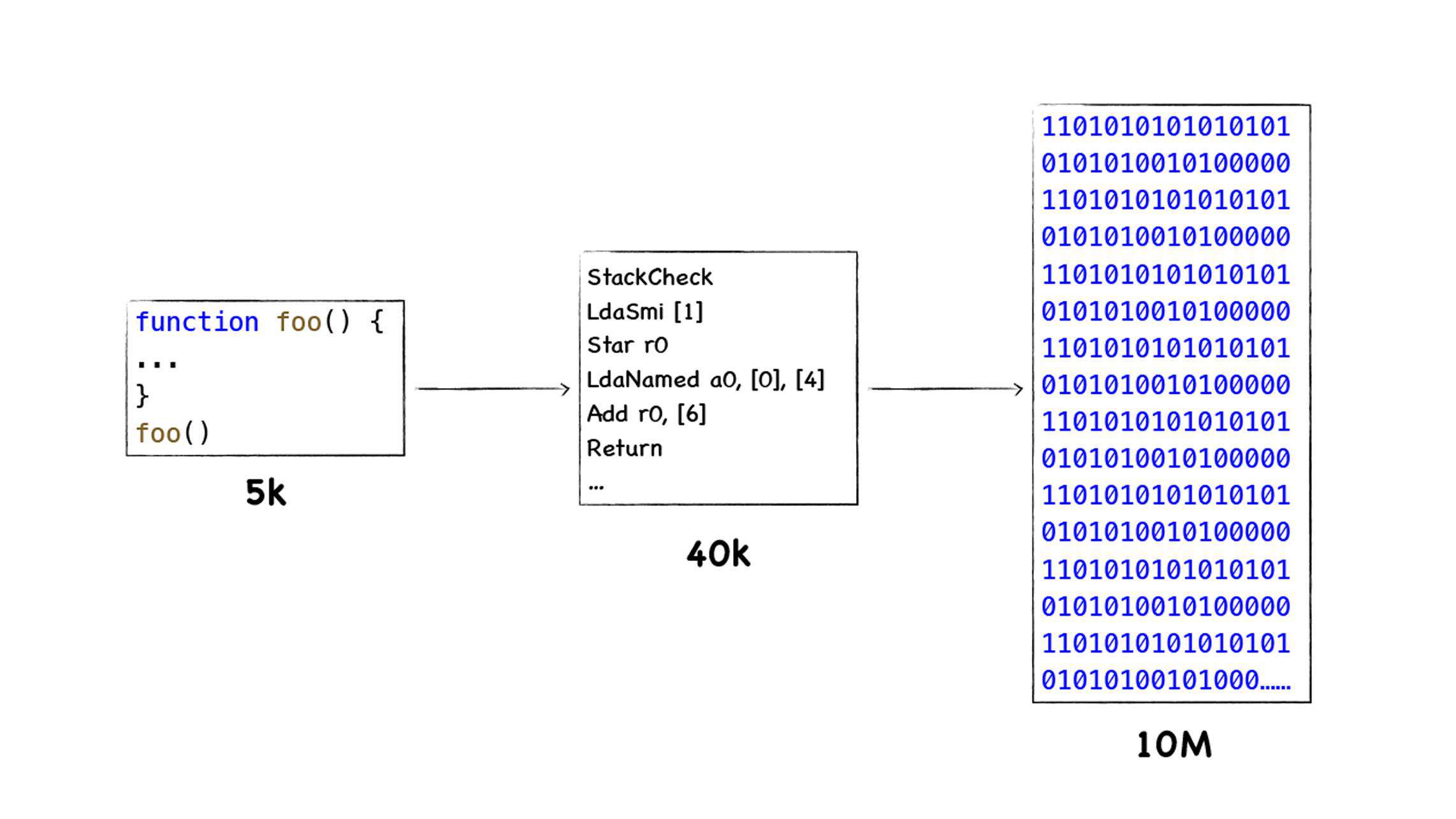
从图中可以看到字节码虽然比JavaScript大很多,但是比起二进制码已经小了很多了。虽然采用字节码在执行速度上稍慢于机器代码,但是整体上权衡利弊,采用字节码也许是最优解。之所以说是最优解,是 因为采用字节码除了降低内存之外,还提升了代码的启动速度,并降低了代码的复杂度,而牺牲的仅仅是一点执行效率。
提升速度&降低复杂度
生成机器代码比生成字节码需要花费更久的时间,但是直接执行机器代码却比解释执行字节码要更高效,所以在快速启动 JavaScript 代码与花费更多时间获得最优运行性能的代码之间,我们需要找到一个平衡点。V8 使用的模型,解释器叫 Ignition,(就原始字节码执行速度而言)是所有引擎中最快的解释器。V8 的优化编译器名为 TurboFan,最终由它生成高度优化的机器码。
早期的 V8 代码是基于 AST 抽象语法树来将代码转换为机器码的,我们知道,不同架构的机器码是不一样的,而市面上存在不同架构的处理器又是非常之多,你可以参看下图:
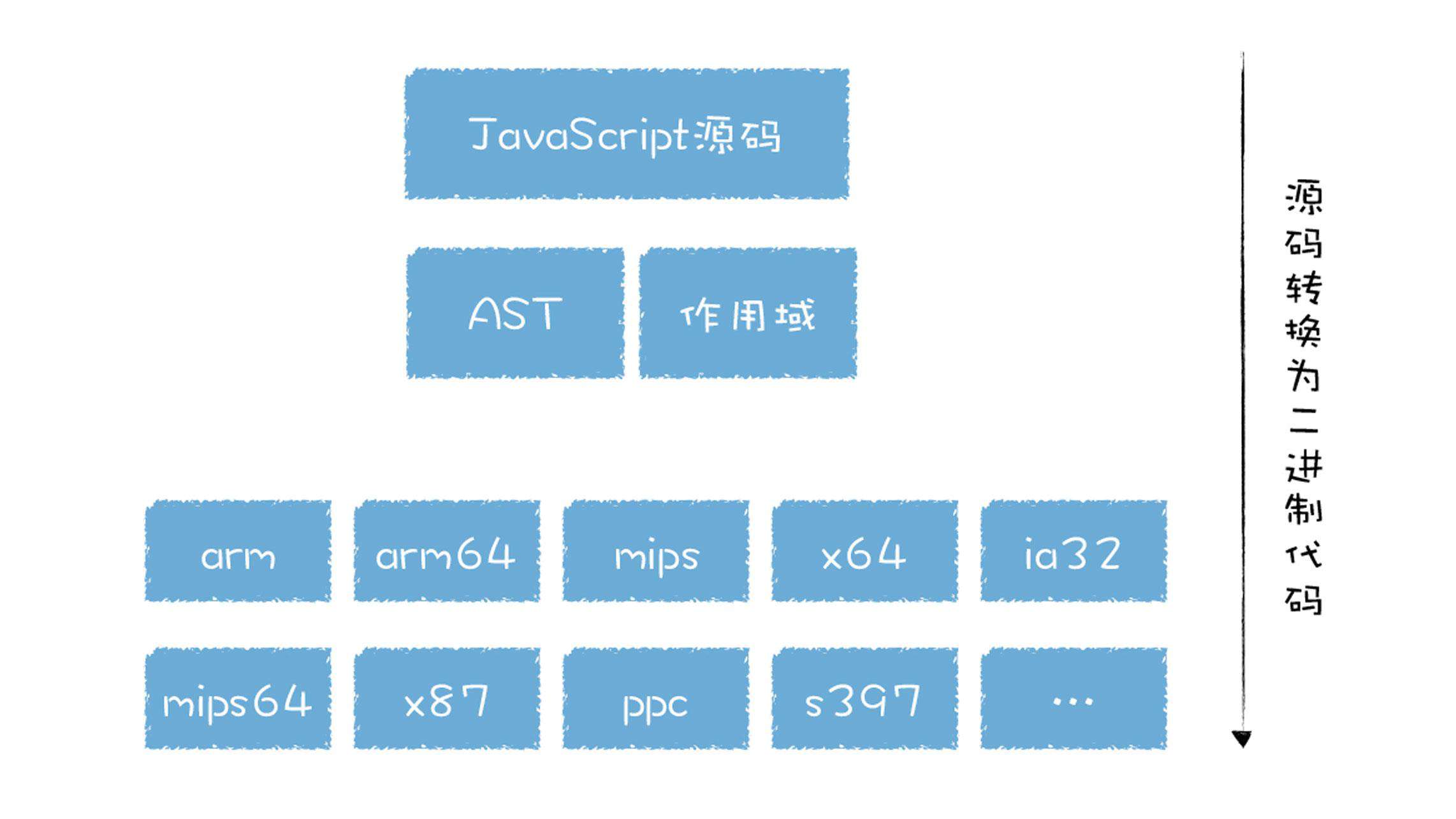
这意味着基线编译器和优化编译器要针对不同的体系的 CPU 编写不同的代码,这会大大增加代码量。引入了字节码,就可以统一将字节码转换为不同平台的二进制代码,你可以对比下执行流程:
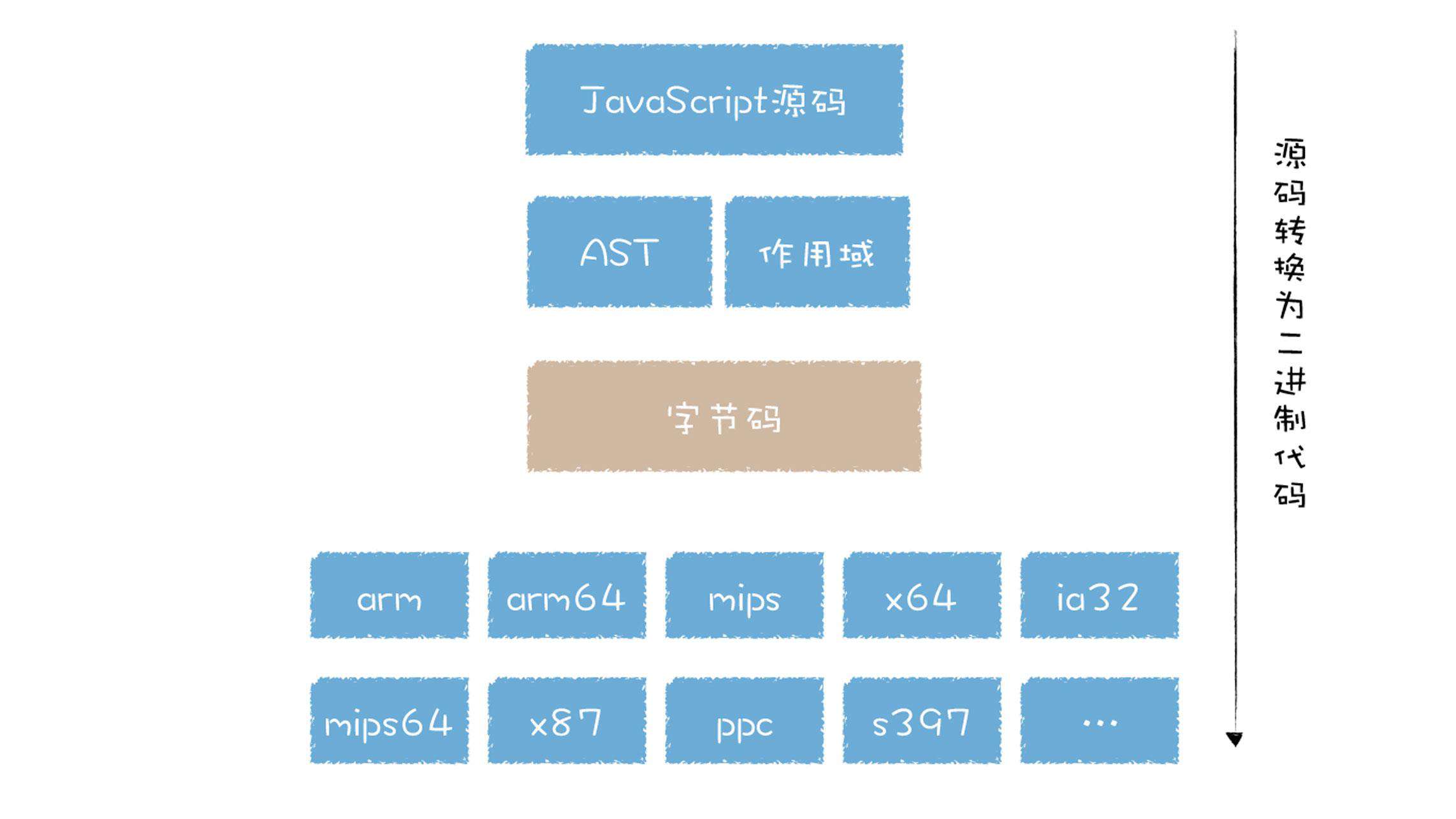
因为字节码的执行过程和 CPU 执行二进制代码的过程类似,相似的执行流程,那么将字节码转换为不同架构的二进制代码的工作量也会大大降低,这就降低了转换底层代码的工作量。
延迟解析
在编译JavaScript代码的过程中,V8 并不会一次将所有的 JavaScript 解析为字节码,处于以下思考:
-
首先,如果一次解析和编译所有的 JavaScript 代码,过多的代码会增加编译时间,这会严重影响到首次执行 JavaScript 代码的速度,让用户感觉到卡顿。因为有时候一个页面的 JavaScript 代码都有 10 多兆,如果要将所有的代码一次性解析编译完成,那么会大大增加用户的等待时间;
-
其次,解析完成的字节码和编译之后的机器代码都会存放在内存中,如果一次性解析和编译所有 JavaScript 代码,那么这些中间代码和机器代码将会一直占用内存,特别是在手机普及的年代,内存是非常宝贵的资源。
基于以上原因,几乎所有的 JavaScript 虚拟机都实现了延迟解析,也称惰性解析。所谓惰性解析就是解析器解析的过程中,如果遇到函数声明,会先跳过函数内部的代码,并不会为其生成 AST 和 字节码,而仅仅生成顶层代码需要的 AST 和字节码。
举个?看看:
function foo(a,b) {
var d = 100
var f = 10
return d + f + a + b;
}
var a = 1
var c = 4
foo(1, 5)
当 V8 拿到代码后,自上而下地解析代码,在解析过程中首先会遇到 foo 函数,由于这只是一个函数声明语句,V8 在这个阶段只会将这个函数转成为一个函数对象,如下图所示:
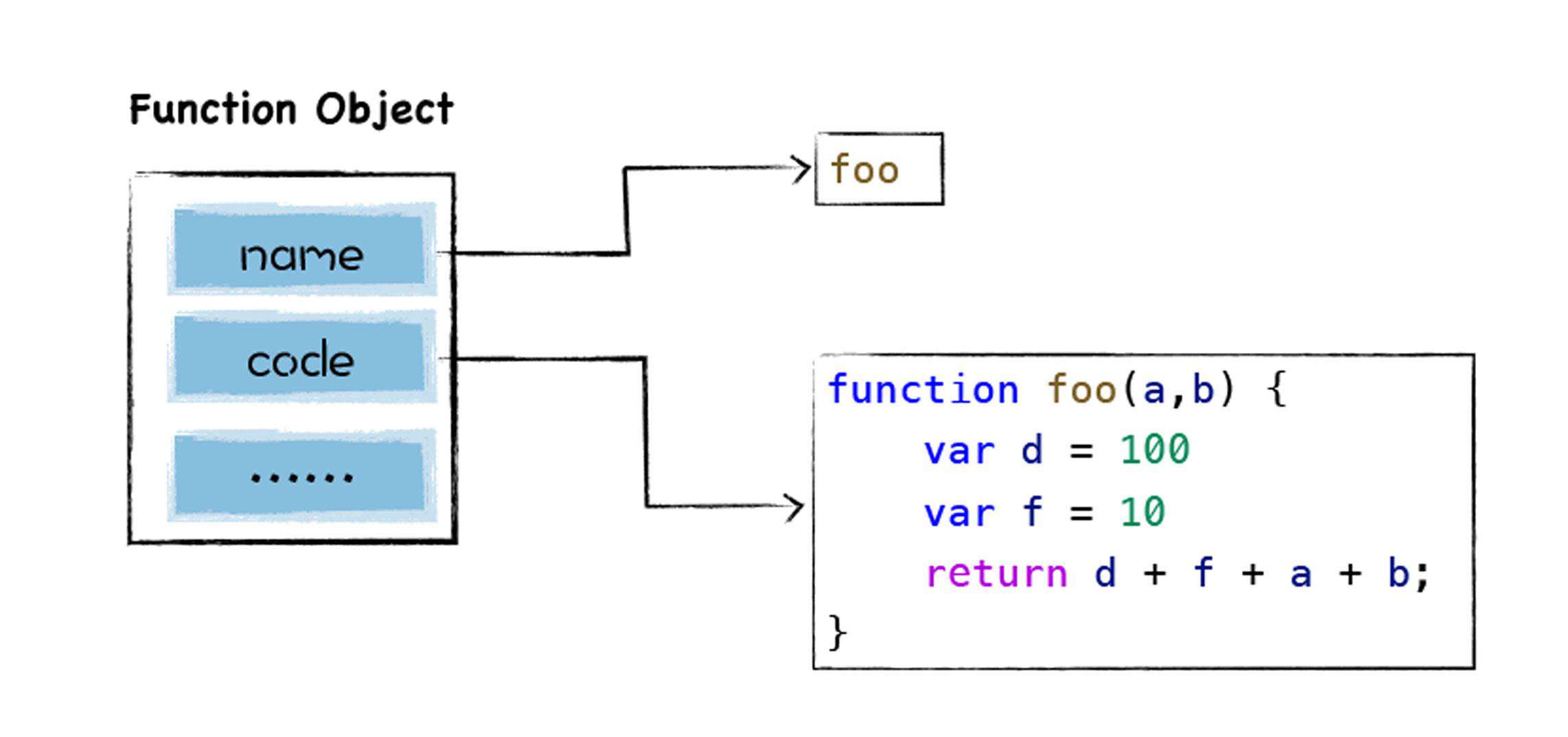
这时并不会解析和编译 foo 函数内部的代码,所以也不会为 foo 函数生成抽象语法树。继续向下解析,由于后续代码都是顶层代码,V8 会为他们生成抽象语法树,最终的结果如下:
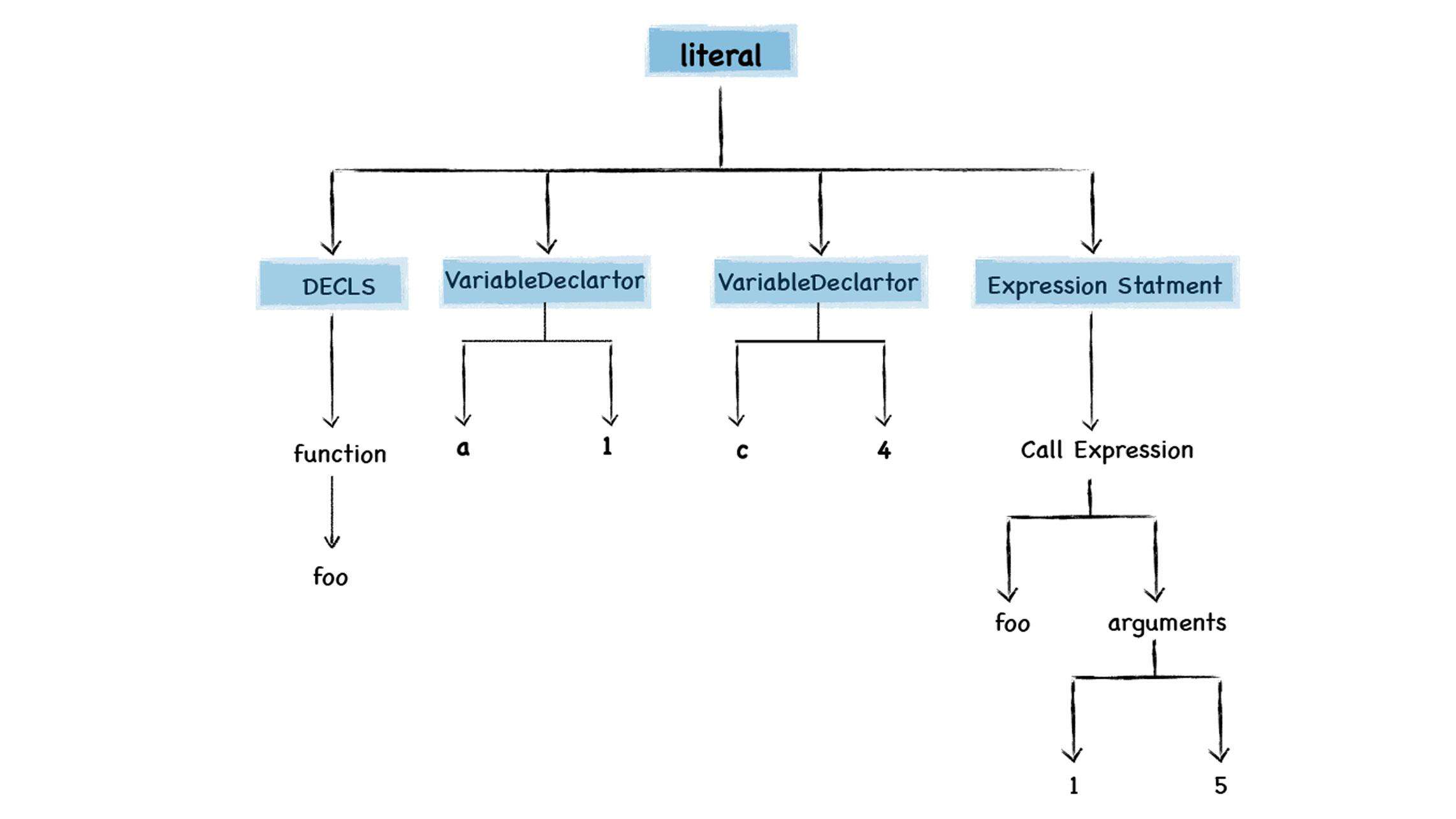
代码解析完成后,V8 会按照顺序自上而下执行代码,首先会执行 a=1 和 c=4 这两个赋值表达式,接下来会执行 foo 函数的调用,过程是从 foo 函数对象中取出函数代码,然后和编译顶层代码一样,V8 会先编译 foo 函数的代码,编译时同样需要先将其编译成抽象语法树和字节码,然后再解析执行。
执行字节码
V8使用 Ignition 解释器来解释执行字节码,我们举个? 看看,这里有一段代码:
function add(x, y) {
var z = x+y
return z
}
console.log(add(1, 2))
生成的字节码是:
StackCheck
Ldar a1
Add a0, [0]
Star r0
LdaSmi [2]
Star r1
Ldar r0
Return
因为解释器就是模拟物理机器来执行字节码的,比如可以实现如取指令、解析指令、执行指令、存储数据等,所以解释器的执行架构和 CPU 处理机器代码的架构类似,我们试着解释一下这段字节码:
StackCheck
Ldar a1 // Ldar表示将寄存器中的某个值加载到累加器中,这个指令是把a1寄存器的值放在累加器中,a1的值是1
Add a0, [0] // 将a0寄存器的值和累加器中的值相加,再存入累加器中,此时寄存器的值是2
Star r0 // 把累加器中的值保存到某个寄存器中,将累加器的值3保存到r0
LdaSmi [2] // 将小整数2加载到寄存器中
Star r1 // 将累加器中的值2保存在r1中
Ldar r0 // 将r0的值3加载进累加器
Return // 结束执行,并将累加器中的值3返回
和汇编语言其实有点像,操作寄存器来计算结果。
通常有两种类型的解释器, 基于栈 (Stack-based)和基于寄存器 (Register-based),基于栈的解释器使用栈来保存函数参数、中间运算结果、变量等,基于寄存器的虚拟机则支持寄存器的指令操作,使用寄存器来保存参数、中间计算结果 。大多数解释器都是基于栈的,比如 Java 虚拟机,.Net 虚拟机,还有早期的 V8 虚拟机,现在的V8 虚拟机则采用了基于寄存器的设计。V8支持的字节码很多,对字节码感兴趣的同学可以到 V8源码 看看~
执行机器码
字节码虽然可以直接解释执行,但是耗时较长,为了优化代码执行速度,V8在解释器内增加了一个监控机器人,在解释执行字节码的过程中,如果发现某一段代码被重复执行多次,那么监控机器人会将这段代码标记为热点代码。
当某段代码被标记为热点代码后,V8就会将这段字节码丢给优化编译器TurboFan,优化编译器会在后台将字节码编译成二进制代码,然后再对编译后的二进制代码进行优化操作,优化后的二进制机器代码的执行效率会得到大幅提升。如果下面再执行到这段代码时,那么 V8 会优先选择优化之后的二进制代码,这样代码的执行速度就会大幅提升。
不过,和静态语言不同的是,JavaScript 是一种非常灵活的动态语言,对象的结构和属性是可以在运行时任意修改的,而经过优化编译器优化过的代码只能针对某种固定的结构,一旦在执行过程中, 对象的结构被动态修改了,那么优化之后的代码势必会变成无效的代码,这时候优化编译器就需要执行反优化操作,经过反优化的代码,下次执行时就会回退到解释器解释执行 。
总结
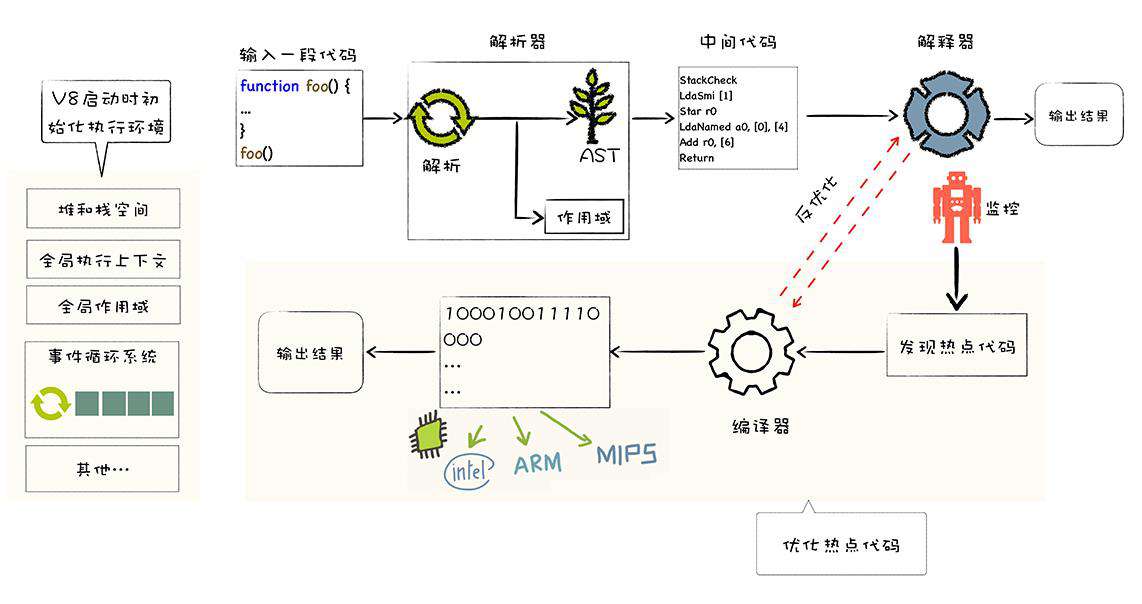
整个编译流水线的流程依次为:
-
初始化基础环境;
-
解析源码生成 AST 和作用域;
-
依据 AST 和作用域生成字节码;
-
解释执行字节码;
-
监听热点代码;
-
优化热点代码为二进制的机器代码;
-
反优化生成的二进制机器代码。
这里值得一提的是,JavaScript 是一门动态语言,在运行过程中,某些被优化的结构可能会被 V8 动态修改了,这会导致之前被优化的代码失效,如果某块优化之后的代码失效了,那么编译器需要执行反优化操作。
最后的话
浏览器原理系列终于迎来了终结篇-《V8编译流水线》,感谢大家的喜欢和支持。笔者才疏学浅,不免有错误和疏漏之处,望大家不吝赐教。
往期回顾
浏览器原理系列-浏览器渲染流程详解
浏览器原理系列-JS执行上下文详解
浏览器原理系列-JS内存机制和垃圾回收
浏览器原理系列-V8引擎对象存储的优化
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!