对于多数人来说,source maps 是个谜。从类型系统到 web bundlers,在多数 Web 的编译方案中都可以找到它。但通常,它们实际构建的细节并不是 100% 透明的,因为仅它们的用法将足够复杂。今天我们将简要概述下什么是 source map 以及如何使用。然后继续学习底层机制:通过构建我们自己的编译器,该编译器会生成一些代码并生成自己的 source map 以供浏览器使用。
这是我的“幕后世界”系列的一部分:
- 类型系统(如 TypeScript)
- React hooks
- Web bundlers(如 Webpack)
以下是本文的概要:
source maps 和编译器简介
- 什么是 source map?为什么有用?
- 使用流行工具的 source maps
- 什么是 AST?
- 转换 JavaScript 的步骤
- 编译器如何构建 source maps
构建自己的编译器
- 构建一个JavaScript代码生成器
- 什么是Base64 VLQ?
- 添加 Source map 支持
- 测试 Source map
Source maps 和编译器简介
什么是 source map?为什么有用?
首先让我们看看为什么人们写需要移植成原生 JavaScript的JavaScript:
- 使用类型系统
- 使用最新的 ES 8-9-10 特性
- 代码优化(例如压缩)
- Bundle 优化(如 vendor 和 app 捆绑)
现代的编译器架构如下所示:

这就是 source maps 的来源!
source map 的基础定义是:
因此,其目的很简单。现代浏览器会自动解析 source map,使它看起来像是你运行的是未压缩或合并的文件。
下面的示例显示了在浏览器中调试 TypeScript 的方法,这只能通过 source map 来实现。
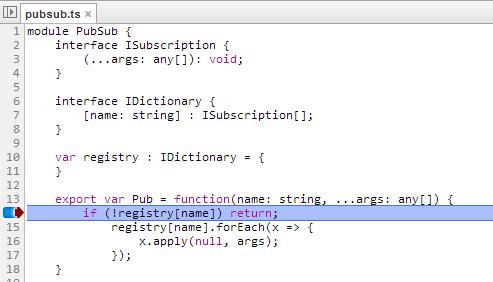
现在,你可以在代码中放置一个断点,在浏览器中检查调用堆栈、变量和任何运行时状态,所有这些都是通过预先编译的TypeScript代码完成的。
2. 使用流行工具的 source maps
有两种方法可以通知浏览器有可用的 source map。
- 在 JS 文件的页脚添加:
//# sourceMappingURL=/path/to/file.js.map - 在 JS 文件的 Header 添加:
X-SourceMap: /path/to/file.js.map
需要注意的几点:
- Chrome只会在DevTools打开的情况下下载 source map (因为它们可能会很大)
- Source map 不会出现在网络请求中(在“network” 选项卡中)
- 获得 source map 后,可以在“源”代码(位于“source”选项卡下)中添加断点。
Source map 标准
现在的 source maps 必须遵循 source map 规范的最新版本。即版本 3,可以在这里找到。规范主要由 Mozilla 和 Google 工程师编写。第3版对整体大小进行了改进,将加快其下载和解析速度。
下面是一个 source map 例子,一个重点是“mappings”,这些是 Base64 VLQ 字符串,包含从源代码到生成的代码的实际映射。稍后我们会自己制作更多关于这个的内容。

流行工具中的用法
Node.js
通过标记 -enable-source-maps
发生异常时,source maps 被缓存并用于堆栈跟踪。
Babel
默认情况下,Babel 会在每个生成的 bundle 的尾部追加一个 source map 位置。例如:
//# sourceMappingURL=file.map.js
通过标记 -source-maps-inline 可以告诉 Babel 使用内联 source map,如下所示(即 base64 编码字符串的内容):
//# sourceMappingURL=data:application/json;charset=utf-8;Base64,...
Webpack
通过配置属性 devtool: 'source-map'
值得注意的是,因为像 Webpack 这样的工具经常使用多个处理器同时执行多个转换(例如 Babel 和 TypeScript),它仍然可以生成单个 source map。每个处理器都将生成自己的 source map,但也有一些库可以连接 JavaScript 文件,同时合并相应的 source maps 文件。mapcat 就是一个例子。
AST 是什么?
在深入讨论之前,我们需要快速了解一下 JavaScript 编译器中重要的机制之一:AST。
AST 指的是“Abstract Synctax Tree”(抽象语法树),本质上是一个“节点”树代表一个程序的代码。“节点”是最小的单位,基本上是一个带有“类型”和“位置”属性的 POJO(即普通的酒 js 对象)。所有的节点都有这两个属性,但根据“类型”,它们还可以有其他各种属性。
在 AST 格式中,代码很容易操作,像添加,删除甚至替换这样的操作。
下面是一个示例代码:

将成为以下 AST:

有些网站,如 astexplorer.next 可以让您编写 JavaScript 代码并立即看到它的 AST。
树的遍历
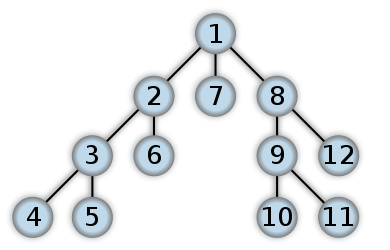
处理 AST 最重要的部分是理解不同的方法,每种方法都有优缺点。
一个流行的例子(我们今天将使用的类型)的例子是“深度优先遍历”,它的工作原理是从根开始,在回溯之前沿着每个分支尽可能向左探索。因此,它将沿着以下顺序处理一棵树:
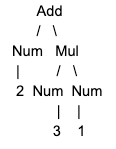
如果我们有一段代码,如:
2 + 3 * 1
将会生成下面的 tree:
转换 JavaScript 的步骤
转换 JavaScript 有三个步骤:
1)将源代码解析为 AST
- 词法分析:将代码字符串转换为 token 流(如 array)
- 语法分析:将 token 流转换为其 AST 表示
2)转换 AST 上的节点
操作 AST 节点(任何库插件都可以在这里操作,例如 babel)
3)生成源代码
将 AST 转换成 JavaScript 源代码字符串
今天我们将重点讨论生成器的工作。
库的不同之处在于只执行一步,或全部执行3个步骤。
实现所有三步的库的例子:
- Babel
- Recast
- Facebooks codemod
只实现一步的库的例子:
- Esprima(做了解析)
- ast-types(做了 AST 节点操作)
- Escodegen(做了生成)
编译器如何构建 source maps
有三个部分来产生一个 source map,所有的编译器必须做:
1) 转换代码并注意新生成的源的位置 2) 检查源代码和生成代码之间的位置差异 3) 使用这些映射构建一个源映射
这是一种过于简化的方法,我们将在下一部分进一步深入。
构建我们自己的编译器
1. 构建一个 JavaScript 代码生成器
我们将从下面的架构开始。目的是在编译后生成转换后的文件(index.es5.js),和 source map(index.es5.js.map)。

我们的 src/index.es6.js 像下面这样(一个简单的添加函数):
function add(number) {
return number + 1;
}
globalThis.add = add;
现在我们有了预编译的源代码。我们要开始看编译器。
步骤
编译器必须执行以下几个步骤:
1. 将代码解析为 AST
由于本文不关注解析,我们将使用一个基本的第三方工具(esprima 或 escodegen)
2. 在 AST 中添加每个节点的浅拷贝
这个思路借鉴了 recast。其思想是:每个节点将保存自己以及自己的拷贝(即原始节点)。拷贝用于检查节点是否已经发生了变化。稍后将详细介绍。
3. 转换
我们将手动执行此操作。我们可以使用 ast-types 或 @babel/types 这样的库,因为它们有有用的 API。
4. 生成源代码
将 AST 转换为 JavaScript
5. 添加 source map 支持
第4步和第5步是同时做的。这将设计遍历树并检测 AST 节点在何处使用其 "original" 属性发生了更改。对于那些实例,存储 “original” 和 “generated” 代码之间的映射。
5. 写入 build/
最后,将生成的源代码及其 souce map 写到对应的文件中。
代码
让我们再看一遍这些步骤,但这次更详细些。
1. 解析代码为 AST
使用第一个基本的第三方工具(我使用的是一个简单的名叫 ast 的工具),我们获取到文件内容将其传递到库解析器中。
import fs from "fs";
import path from "path";
import ast from "abstract-syntax-tree";
const file = "./src/index.es6.js";
const fullPath = path.resolve(file);
const fileContents = fs.readFileSync(fullPath, "utf8");
const sourceAst = ast.parse(fileContents, { loc: true });
2. 在 AST 中添加每个节点的浅拷贝
首先,我们定义一个名为 "visit" 的函数,它的任务是遍历树并在每个节点上执行回调函数。
export function visit(ast, callback) {
callback(ast);
const keys = Object.keys(ast);
for (let i = 0; i < keys.length; i++) {
const keyName = keys[i];
const child = ast[keyName];
if (keyName === "loc") return;
if (Array.isArray(child)) {
for (let j = 0; j < child.length; j++) {
visit(child[j], callback);
}
} else if (isNode(child)) {
visit(child, callback);
}
}
}
function isNode(node) {
return typeof node === "object" && node.type;
}
这里我们做的是上面提到的 “深度优先遍历”。对于给定的节点,它将:
- 执行回调
- 检查是否是“loc”属性,如果是,尽早返回
- 检查任何属于数组的属性,如果是,则每个子对象调用 visit
- 检查任何属于 AST 节点的属性,如果是,则使用该节点调用 visit
接下来我们开始克隆。
export const cloneOriginalOnAst = ast => {
visit(ast, node => {
const clone = Object.assign({}, node);
node.original = clone;
});
};
cloneOriginalAst 函数生成节点的拷贝,并将其附加到原始节点上。
我们使用 Object.assign 进行克隆,它是一个浅拷贝,并复制顶级属性。嵌套的属性仍然是通过引用传递连接的,即改变它们将改变克隆值。我们也可以在这里使用扩展操作符,作用是一样的。我们将使用顶层进行比较,这足以比较两个 AST 节点并确定节点是否发生了更改。
总的来说,我们在这里的代码将返回相同的树,除了在每个节点上都带有 “original”属性。
3. 转换
接下来,我们将进行节点操作。我们将保持它的简洁,因此仅仅是从我们的程序中交换两个节点。因此我们将从
number + 1
改变为:
1 + number
理论上很简单,对吧!
下面是我们进行交换的代码:
// Swap: "number + 1"
// - clone left node
const leftClone = Object.assign(
{},
sourceAst.body[0].body.body[0].argument.left
);
// - replace left node with right node
sourceAst.body[0].body.body[0].argument.left =
sourceAst.body[0].body.body[0].argument.right;
// - replace right node with left clone
sourceAst.body[0].body.body[0].argument.right = leftClone;
// Now: "1 + number". Note: loc is wrong
我们没有使用一个简洁的 API 来完成这个任务(许多库都有提供),因为我们手动交换了两个节点。
使用带有 API 的库的示例如下所示,由 ast-types 文档提供。

这种方式当然更安全,更容易遵循和更快的开发。因此,一般来说,我建议在任何复杂的 AST 操作中使用它,大多数知名的编译器都是这样做的。
4. 生成源代码
代码生成器通常位于单个文件中,有几千行代码。例如,escodegen的编译器是2619行(见这里)。与其他的相比,这是较小的了。
我已经为我们的编译器使用了大部分相同的代码(因为大多数生成器需要非常相似的逻辑来将 AST 处理成 JavaScript),除了处理index.es6.js 文件中的代码必不可少的部分。
a) 节点处理器和字符工具集
这些是用于处理 AST 节点的通用实用函数(取决于类型,例如函数声明将有一个标识符)和构建源代码。它还包括一些常见的字符常量(例如“空格”)。在下一节的代码“类型语句”中调用它们。
我不会太担心这里的细节,除非您计划编写一个编译器。这很大程度上是借用了escodegen的生成器。
// Common characters
const space = " ";
const indent = space + space;
const newline = "\n";
const semicolon = ";"; // USUALLY flags on this
// Utility functions
function parenthesize(text, current, should) {
if (current < should) {
return ["(", text, ")"];
}
return text;
}
const generateAssignment = (left, right, operator, precedence) => {
const expression = [
generateExpression(left),
space + operator + space,
generateExpression(right)
];
return parenthesize(expression, 1, precedence).flat(); // FLATTEN
};
const generateIdentifier = id => {
return id.name;
};
const generateFunctionParams = node => {
const result = [];
result.push("(");
result.push(node.params[0].name); // USUALLY lots of logic to grab param name
result.push(")");
return result;
};
const generateStatement = node => {
const result = Statements[node.type](node);
return result;
};
const generateFunctionBody = node => {
const result = generateFunctionParams(node);
return result.concat(generateStatement(node.body)); // if block generateStatement
};
const generateExpression = node => {
const result = Statements[node.type](node);
return result;
};
b) 类型声明
这是一个包含与 AST 节点类型绑定的函数的对象。每个节点都包含处理 AST 节点类型和生成源代码所需的逻辑。例如,对于函数声明,它包含所有可能的参数、标识符、逻辑和返回类型的变化。这里有一种常见的递归级别,即一个类型语句触发另一个类型语句,该类型语句可能触发另一个类型语句,等等。
这里,我们只有处理 “index.es6.js” 文件所需的语句函数,所以它相当有限。您可以看到仅处理 3-4 行代码的 AST 树(除了上面的部分)就需要多少代码。
同样,这借用了“escodegen here”,所以请随意忽略细节,除非你计划编写自己的编译器。
const Statements = {
FunctionDeclaration: function(node) {
let id;
if (node.id) {
id = generateIdentifier(node.id);
} else {
id = "";
}
const body = generateFunctionBody(node);
return ["function", space, id].concat(body); // JOIN
},
BlockStatement: function(node) {
let result = ["{", newline];
// USUALLY withIndent OR for loop on body OR addIndent
result = result.concat(generateStatement(node.body[0])).flat();
result.push("}");
result.push("\n");
return result;
},
ReturnStatement: function(node) {
// USUALLY check for argument else return
return [
indent,
"return",
space,
generateExpression(node.argument),
semicolon,
newline
];
},
BinaryExpression: function(node) {
const left = generateExpression(node.left);
const right = generateExpression(node.right);
return [left, space, node.operator, space, right];
},
Literal: function(node) {
if (node.value === null) {
return "null";
}
if (typeof node.value === "boolean") {
return node.value ? "true" : "false";
}
return node.value;
},
Identifier: function(node) {
return generateIdentifier(node);
},
ExpressionStatement: function(node) {
const result = generateExpression(node.expression); // was []
result.push(";");
return result;
},
AssignmentExpression: function(node, precedence) {
return generateAssignment(node.left, node.right, node.operator, precedence);
},
MemberExpression: function(node, precedence) {
const result = [generateExpression(node.object)];
result.push(".");
result.push(generateIdentifier(node.property));
return parenthesize(result, 19, precedence);
}
};
c) 处理代码语句
最后,我们将遍历程序主体(即每一行代码)并开始运行我们的生成器。这将返回一个名为“code”的数组,其中包含了我们新生成的源代码的每一行。
const code = ast.body
.map(astBody => Statements[astBody.type](astBody))
.flat();
6. 写进 build/
我们现在将跳过第5步,并完成编译器的核心元素。这一步我们会:
- 向生成的代码中添加 source map 位置(我们将在下一节中构建它)
- 为生成的代码生成一个包(将我们的代码数组连接在一起),并复制原始代码以便浏览器可以看到它(这只是一种方法)。
// Add sourcemap location
code.push("\n");
code.push("//# sourceMappingURL=/static/index.es5.js.map");
// Write our generated and original
fs.writeFileSync(`./build/index.es5.js`, code.join(""), "utf8");
fs.writeFileSync(`./build/index.es6.js`, fileContents, "utf8");
5. 添加 Source map 支持
构建 source map 有4个要求:
- 保存源文件的记录
- 存储生成文件的记录
- 存储行/列的映射
- 使用 spec version3 显示在源映射文件中
为了快速取胜,我们可以使用几乎所有 JavaScript 代码生成器都使用的名为 source-map 的库。它来自 Mozilla,处理点1-3的存储以及到 Base64 VLQ 的映射处理(步骤4)。
提醒一下,当 mappings 高亮显示时,source maps 是什么样子的(从上面开始):

mappings 是 Base64 VLQ,但那是什么?
什么是 Base64 VLQ?
首先简要介绍一下 Base64 和 VLQ。
Base64
解决了处理没有完整 ASCII 字符集的语言的 ASCII 问题。Base64 只有 ASCII 的一个子集,这更容易在不同的语言中处理。
VLQ(variable-length quantity,变长量)
将一个整数的二进制表示形式分解为一组由可变位组成的小块。
Base64 VLQ
经过优化,可以很容易地在大数和源文件中的相应信息之间进行映射。
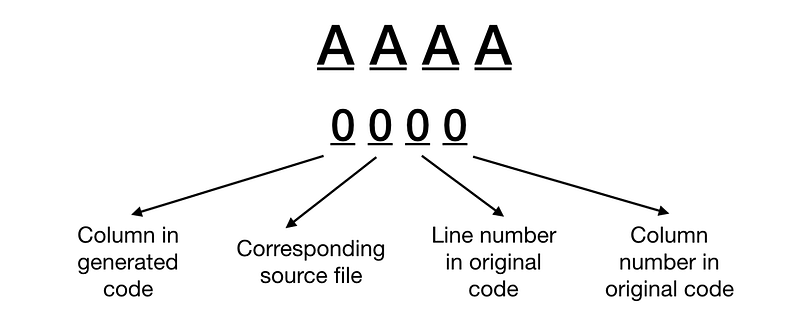
一行代码用一系列 “segments” 表示。数字 “1” 将是:AAAA => 0000
以下是如何建立一个 “Segment” 的例子:
在 JavaScript 中构建一个基本的映射如下:
// .. define "item"
const sourceArray = [];
sourceArray.push(item.generated.column);
sourceArray.push("file.es6.js");
sourceArray.push(item.source.line);
sourceArray.push(item.source.column);
const encoded = vlq.encode(sourceArray);
然而,这不能处理行和段分割(这可能非常棘手),因此使用 Mozilla 的库仍然更有效。
添加 source map 支持
回到我们的编译器。
使用mozilla SourceMapGenerator
为充分利用 Mozillas 库,我们会:
- 创建一个 sourceMap 实例来保存和构建我们的映射
- 初始化并存储本地映射
所以当一个节点发生变化的时候,我们将构建位置,然后将其添加到本地映射和 SourceMap 实例中。我们保留一个本地实例,这样我们就可以保存当前位置的 start 和 end 记录,因为这对构建下一个位置至关重要。
// SourceMap instance
const mozillaMap = new SourceMapGenerator({
file: "index.es5.js"
});
// Local mappings instance
const mappings = [
{
target: {
start: { line: 1, column: 0 },
end: { line: 1, column: 0 }
},
source: {
start: { line: 1, column: 0 },
end: { line: 1, column: 0 }
},
name: "START"
}
];
我们需要一个函数来实际处理这些映射实例的更新。下面的 buildLocation 函数处理所有位置生成逻辑。大多数库都有一个类似的函数,使用调用者给出的列和行的偏移量。
它的工作是计算出新的行号和列号的开始以及行号和列号的结束。它只会在节点发生变化时添加映射,这限制了我们要存储的映射。
const buildLocation = ({
colOffset = 0, lineOffset = 0, name, source, node
}) => {
let endColumn, startColumn, startLine;
const lastGenerated = mappings[mappings.length - 1].target;
const endLine = lastGenerated.end.line + lineOffset;
if (lineOffset) {
endColumn = colOffset;
startColumn = 0; // If new line reset column
startLine = lastGenerated.end.line + lineOffset;
} else {
endColumn = lastGenerated.end.column + colOffset;
startColumn = lastGenerated.end.column;
startLine = lastGenerated.end.line;
}
const target = {
start: {
line: startLine,
column: startColumn
},
end: {
line: endLine,
column: endColumn
}
};
node.loc = target; // Update node with new location
const clonedNode = Object.assign({}, node);
delete clonedNode.original; // Only useful for check against original
const original = node.original;
if (JSON.stringify(clonedNode) !== JSON.stringify(original)) {
// Push to real mapping. Just START. END is for me managing state
mozillaMap.addMapping({
generated: {
line: target.start.line,
column: target.start.column
},
source: sourceFile,
original: source.start,
name
});
}
return { target };
};
现在我们有了 buildLocation 我们需要在代码中引入它。下面是几个例子。对于 generateIdentifier 处理器实用程序和 Literal AST 类型语句,您可以看到我们如何合并 buildLocation。
// Processor utility
const generateIdentifier = id => {
mappings.push(
buildLocation({
name: `_identifier_ name ${id.name}`,
colOffset: String(id.name).length,
source: id.original.loc,
node: id
})
);
return id.name;
};
// AST type statement function (part of "Statements" object)
Literal: function(node) {
mappings.push(
buildLocation({
name: `_literal_ value ${node.value}`,
colOffset: String(node.value).length,
source: node.original.loc,
node
})
);
if (node.value === null) {
return "null";
}
if (typeof node.value === "boolean") {
return node.value ? "true" : "false";
}
return node.value;
};
我们需要在整个代码生成器中应用这一点(即所有节点处理器和 AST 类型语句函数)。
我发现这很棘手,因为节点到字符的映射并不总是 1-2-1。例如,一个函数可以在其参数的任意一侧使用方括号,当涉及到字符行位置时,必须考虑到这一点。所以:
(one) =>
有不同的字符位置:
one =>
大多数库所做的是使用 AST 节点上的信息引入逻辑和防御检查,这样就可以涵盖所有场景。我本应该遵循相同的实践,除非我只是为我们的 index.es6.js 添加绝对必要的代码。
要了解完整的用法,请参阅存储库中我的生成器的代码。它缺少大块的代码,但它完成了工作,是真正的代码生成器的构建块。
最后一部分是将我们的 source map 内容写入 source map 文件。这在 Mozillas 库中非常简单,因为他们公开了一个 toString() 方法,该方法将处理 Base64 VLQ 编码,并将所有映射构建到一个符合 v3 规范的文件中。不错! !
// From our Mozilla SourceMap instance
fs.writeFileSync(`./build/index.es5.js.map`, mozillaMap.toString(), "utf8");
现在我们前面引用的 ./build/index.es5.js 将有一个已经存在的文件。
我们的编译器现在完成了!
对编译器来说,这就是最后一部分,现在得到确认,它已经工作。
如果我们编译代码,它将生成包含3个文件的构建文件夹。
$ npm run compile
这是原始文件、生成的文件和 source map。
测试我们的 source map
有一个很棒的网站 sokra.github.io/source-map-… 它允许你可视化 source map mappings。
页面的开头是这样的:
通过把我们的3个文件放进去,我们现在可以看到:
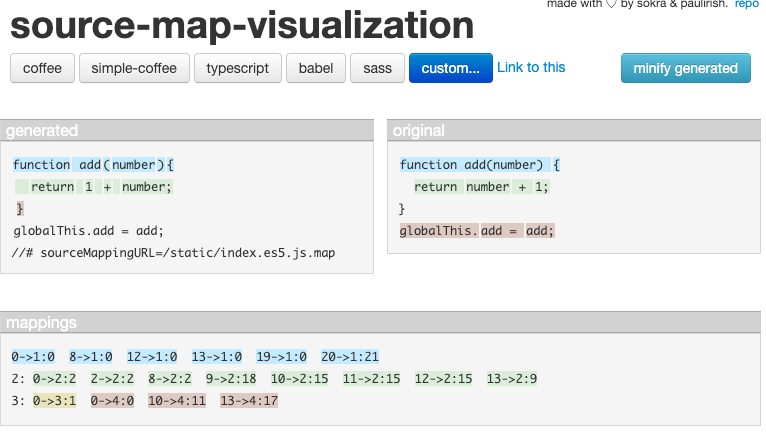
它包含原始代码、生成的代码和已解码的映射(在底部)。
提醒一下我们之前的转换:
// Swap: "number + 1"
// - clone left node
const leftClone = Object.assign(
{},
sourceAst.body[0].body.body[0].argument.left
);
// - replace left node with right node
sourceAst.body[0].body.body[0].argument.left =
sourceAst.body[0].body.body[0].argument.right;
// - replace right node with left clone
sourceAst.body[0].body.body[0].argument.right = leftClone;
// Now: "1 + number". Note: loc is wrong
我们有交换:
number + 1
为:
1 + number
我们可以确认映射成功了吗?
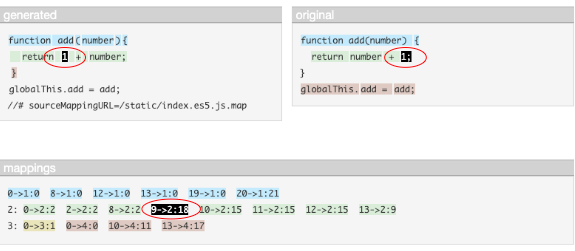
如果我们将鼠标悬停在字符或映射上,它将突出显示映射及其在生成和原始位置中的相应位置。
下面的截图显示了当鼠标悬停在数字“1”字符上时的情况。它清楚地表明存在映射。
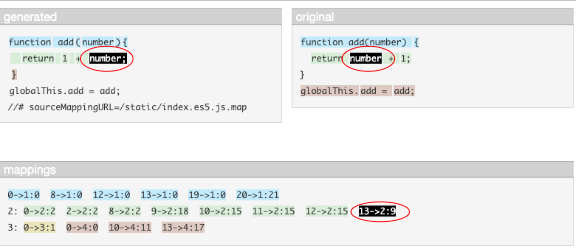
这张截图显示了当我将鼠标悬停在变量标识符“number”单词上时发生的情况。它清楚地表明存在映射。
我们错过了什么?
那么,构建这样的编译器有什么限制呢?
-
并不是所有的 JavaScript 语句都被覆盖了(只覆盖了文件需要的部分)
-
目前它只工作于一个文件。Web bundlers 将遵循应用程序构建依赖关系图,并在这些文件上应用转换(请参阅我的“Web bundlers 的底层”文章了解更多这方面的信息)。
-
输出文件 vs bundle。Web bundlers 将产生在特定 JavaScript 环境下可以运行的代码,我们的 bundler 非常有限。
-
基本变换。如果没有大量的新代码,执行额外的优化并不容易。
非常感谢你的阅读。这个课题意义深远,在研究过程中我学到了很多。我真的希望这篇文章能够帮助大家了解 JavaScript 编译器和 source maps 是如何一起工作的,包括所涉及的机制。
源代码可以在 craigtaub/our-own-babel-sourcemap 上找到。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!