除了我们本身拥有的自带内置库,想要找可以服务需求的库,如果软件里没有,那么基本上都是第三方库了,小编这就遇到了需要安装第三库的情况,主要还是有个需求,需要去分析文本内容,还要是能在搜索完成后,进行搜索结果的检索,然后在精确的提出我的需求,像这样的库,就是今天我们要说的jieba库。
jieba库的作用:
检索文本文档,并精准的做中文分词
安装方法:
pip install jieba #或者 pip3 install jieba
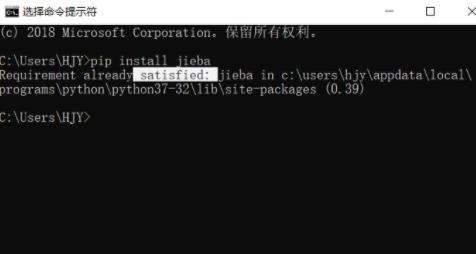
测试安装是否成功:
jieba库实例使用:
seg_list = jieba.cut("中国上海是一座美丽的国际性大都市", cut_all=False)
print("Full Mode: " + "/ ".join(seg_list))返回结果:
Default Mode: 中国/ 上海/ 是/ 一座/ 美丽/ 的/ 国际性/ 大都市
仔细看下,不难发现jieba库搭配cut方法,可以做精确的分析,看到这里,想必都已经掌握了解了,赶紧带入实例项目里试试吧。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!