在 Python 开发中,我们经常听到有关「容器」、「迭代器」、「可迭代对象」、「生成器」的概念。
我们经常把这些概念搞混淆,它们之间有哪些联系和区别呢?
这篇文章,我们就来看一下它们之间的关系。
容器
首先,我们先来看一下容器是如何定义的?
简单来说,容器就是存储某些元素的统称,它最大的特性就是判断一个元素是否在这个容器内。
怎么理解这句话?
很简单,在 Python 中,我们通常使用 in 或 not in 来判断一个元素存在/不存在于一个容器内。
例如下面这个例子:
print('x' in 'xyz') # True
print('a' not in 'xyz') # True
print(1 in [1, 2, 3]) # True
print(2 not in (1, 2, 3)) # False
print('x' not in {'a', 'b', 'c'}) # True
print('a' in {'a': 1, 'b': 2}) # True
在这个例子中,我们可以看到 str、list、tuple、set、dict 都可以通过 in 或 not in 来判断一个元素是否在存在/不存在这个实例中,所以这些类型我们都可以称作「容器」。
那为什么这些「容器」可以使用 in 或 not in 来判断呢?
这是因为它们都实现了 __contains__ 方法。
如果我们也想自定义一个容器,只需像下面这样,在类中定义 __contains__ 方法就可以了:
class A:
def __init__(self):
self.items = [1, 2]
def __contains__(self, item):
return item in self.items
a = A()
print(1 in a) # True
print(2 in a) # True
print(3 in a) # False
在这个例子中,类 A 定义了 __contains__ 方法,所以我们就可以使用 1 in a 的方式去判断这个元素是否在 A 这个容器内。
换句话说,一个类只要实现了 __contains__ 方法,那么它就是一个「容器」。
我们在开发时,除了使用 in 判断元素是否在容器内之外,另外一个常用的功能是:输出容器内的所有元素。
例如执行 for x in [1, 2, 3],就可以迭代出容器内的所有元素。
那使用这种方式输出元素,是如何实现的?这就跟「迭代器」有关了。
迭代器
一个对象要想使用 for 的方式迭代出容器内的所有数据,这就需要这个类实现「迭代器协议」。
也就是说,一个类如果实现了「迭代器协议」,就可以称之为「迭代器」。
什么是「迭代器协议」呢?
在 Python 中,实现迭代器协议就是实现以下 2 个方法:
__iter__:这个方法返回对象本身,即self__next__:这个方法每次返回迭代的值,在没有可迭代元素时,抛出StopIteration异常
下面我们来看一个实现迭代器协议的例子:
# coding: utf8
class A:
"""A 实现了迭代器协议 它的实例就是一个迭代器"""
def __init__(self, n):
self.idx = 0
self.n = n
def __iter__(self):
print('__iter__')
return self
def __next__(self):
if self.idx < self.n:
val = self.idx
self.idx += 1
return val
else:
raise StopIteration()
# 迭代元素
a = A(3)
for i in a:
print(i)
# 再次迭代 没有元素输出 因为迭代器只能迭代一次
for i in a:
print(i)
# __iter__
# 0
# 1
# 2
# __iter__
在这个例子中,我们定义了一个类 A,它内部实现了 __iter__ 和 __next__ 方法。
其中 __iter__ 方法返回了 self,__next__ 方法实现了具体的迭代细节。
然后执行 a = A(3),在执行 for i in a 时,我们看到调用了 __iter__ 方法,然后依次输出 __next__ 中的元素。
其实在执行 for 循环时,实际执行流程是这样的:
for i in a相当于执行iter(a)- 每次迭代时会执行一次
__next__方法,返回一个值 - 如果没有可迭代的数据,抛出
StopIteration异常,for会停止迭代
但是请注意,当我们迭代完 for i in a 时,如果再次执行迭代,将不会有任何数据输出。
如果我们想每次执行都能迭代元素,只需每次迭代一个新对象即可:
# 每次都迭代一个对象
for i in A(3):
print(i)
可迭代对象
明白了「迭代器」是如何执行的,我们接着来看什么是「可迭代对象」?
这是什么意思?难道一个类是「迭代器」,那么它的实例不是一个「可迭代对象」吗? 它们之间又有什么区别?
其实,但凡是可以返回一个「迭代器」的对象,都可以称之为「可迭代对象」。
换句话说:__iter__ 方法返回一个迭代器,那么这个对象就是「可迭代对象」。
听起来不太好理解,我们来看一个例子。
class A:
# A是迭代器 因为它实现了 __iter__ 和__next__方法
def __init__(self, n):
self.idx = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.idx < self.n:
val = self.idx
self.idx += 1
return val
else:
raise StopIteration()
class B:
# B不是迭代器 但B的实例是一个可迭代对象
# 因为它只实现了 __iter__
# __iter__返回了A的实例 迭代细节交给了A
def __init__(self, n):
self.n = n
def __iter__(self):
return A(self.n)
# a是一个迭代器 同时也是一个可迭代对象
a = A(3)
for i in a:
print(i)
# <__main__.A object at 0x10eb95550>
print(iter(a))
# b不是迭代器 但它是可迭代对象 因为它把迭代细节交给了A
b = B(3)
for i in b:
print(i)
# <__main__.A object at 0x10eb95450>
print(iter(b))
仔细看这个例子,我们定义了 2 个类 A 和 B,A 实现了 __iter__ 和 __next__ 方法。
而 B 只实现了 __iter__,并没有实现 __next__,而且它的 __iter__ 返回值是一个 A 的实例。
对于 A 来说:
A是一个「迭代器」,因为其实现了迭代器协议__iter__和__next__- 同时
A的__iter__方法返回了实例本身self,也就是说返回了一个迭代器,所以A的实例a也是一个「可迭代对象」
对于B 来说:
B不是一个「迭代器」,因为它只了实现__iter__,没有实现__next__- 由于
B的__iter__返回了A的实例,而A是一个迭代器,所以B的实例b是一个「可迭代对象」,换句话说,B把迭代细节交给了A
总之,一个类的迭代细节,是可以交给另一个类的,就像这个例子的 B 这样,所以 B 的实例只能是「可迭代对象」,而不是「迭代器」。
其实,这种情况我们见的非常多,我们使用最多的 list、tuple、set、dict 类型,都只是「可迭代对象」,但不是「迭代器」,因为它们都是把迭代细节交给了另外一个类,这个类才是真正的迭代器。
看下面这个例子,你就能明白这两者之间的差别了。
# list 是可迭代对象
>>> l = [1, 2]
# list 的迭代器是 list_iterator
>>> iter(l)
<list_iterator object at 0x1009c1c18>
# 执行的是 list_iterator 的 __next__
>>> iter(l).__next__()
>>> 1
# tuple 是可迭代对象
>>> t = ('a', 'b')
# tuple 的迭代器是 tuple_iterator
>>> iter(t)
<tuple_iterator object at 0x1009c1b00>
# 执行的是 tuple_iterator 的 __next__
>>> iter(t).__next__()
>>> a
# set 是可迭代对象
>>> s = {1, 2}
# set 的迭代器是 set_iterator
>>> iter(s)
<set_iterator object at 0x1009c70d8>
# 执行的是 set_iterator 的 __next__
>>> iter(s).__next__()
>>> 1
# dict 是可迭代对象
>>> d = {'a': 1, 'b': 2}
# dict 的迭代器是 dict_keyiterator
>>> iter(d)
# 执行的是 dict_keyiterator 的 __next__
<dict_keyiterator object at 0x1009c34f8>
>>> iter(d).next()
>>> a
以 list 类型为例,我们先定义 l = [1, 2],然后执行 iter(l) 得到 list 类型的迭代器是 list_iterator,也就是说在迭代 list 时,其实执行的是 list_iterator 的 __next__,list 把具体的迭代细节,交给了 list_iterator。
所以 list 是一个可迭代对象,但它不是迭代器。其他类型 tuple、set、dict 也是同样的道理。
由此我们可以得出一个结论:迭代器一定是个可迭代对象,但可迭代对象不一定是迭代器。
生成器
我们再来看什么是「生成器」?
其实,「生成器」是一个特殊的「迭代器」,并且它也是一个「可迭代对象」。
有 2 种方式可以创建一个生成器:
- 生成器表达式
- 生成器函数
用生成器表达式创建一个生成器的例子如下:
# 创建一个生成器 类型是 generator
>>> g = (i for i in range(5))
>>> g
<generator object <genexpr> at 0x101334f50>
# 生成器就是一个迭代器
>>> iter(g)
<generator object <genexpr> at 0x101334f50>
# 生成器也是一个可迭代对象
>>> for i in g:
... print(i)
# 0 1 2 3 4
注意看这个例子,我们使用 g = (i for i in range(5)) 创建了一个生成器,它的类型是 generator,同时调用 iter(g) 可以得知 __iter__ 返回的是实例本身,即生成器也是一个迭代器,并且它也是一个可迭代对象。
再来看用函数创建一个生成器:
def gen(n):
for i in range(n):
yield i
# 创建一个生成器
g = gen(5)
# <generator object gen at 0x10bb46f50>
print(g)
# <type 'generator'>
print(type(g))
# 迭代这个生成器
for i in g:
print(i)
# 0 1 2 3 4
在这个例子中,我们在函数中使用 yield 关键字。其实,包含 yield 关键字的函数,不再是一个普通的函数,而返回的是一个生成器。它在功能上与上面的例子一样,可以迭代生成器中的所有数据。
通常情况下,我们习惯在函数内使用 yield 的方式来创建一个生成器。
但是,使用生成器迭代数据相比于普通方式迭代数据,有什么优势呢?
这就要来看一下使用 yield 的函数和使用 return 的普通函数,有什么区别了。
使用 yield 的函数与使用 return 的函数,在执行时的差别在于:
- 包含
return的方法会以return关键字为最终返回,每次执行都返回相同的结果 - 包含
yield的方法一般用于迭代,每次执行时遇到yield就返回yield后的结果,但内部会保留上次执行的状态,下次继续迭代时,会继续执行yield之后的代码,直到再次遇到yield后返回
当我们想得到一个集合时,如果使用普通方法,只能一次性创建出这个集合,然后 return 返回:
def gen_data(n):
# 创建一个集合
return [i for i in range(n)]
但如果此时这个集合中的数据非常多,我们就需要在内存中一次性申请非常大的内存空间来存储。
如果我们使用 yield 生成器的方式迭代这个集合,就能解决内存占用大的问题:
for gen_data(n):
for i in range(n):
# 每次只返回一个元素
yield i
使用生成器创建这个集合,只有在迭代执行到 yield 时,才会返回一个元素,在这个过程中,不会一次性申请非常大的内存空间。当我们面对这种场景时,使用生成器就非常合适了。
其实,生成器在 Python 中还有很大的用处,我会在后面的文章讲解 yield 时,再进行详细的分析。
总结
总结一下,这篇文章我们主要分析了 Python 中「容器」、「迭代器」、「可迭代对象」、「生成器」的联系和区别,用一张图表示它们的关系:
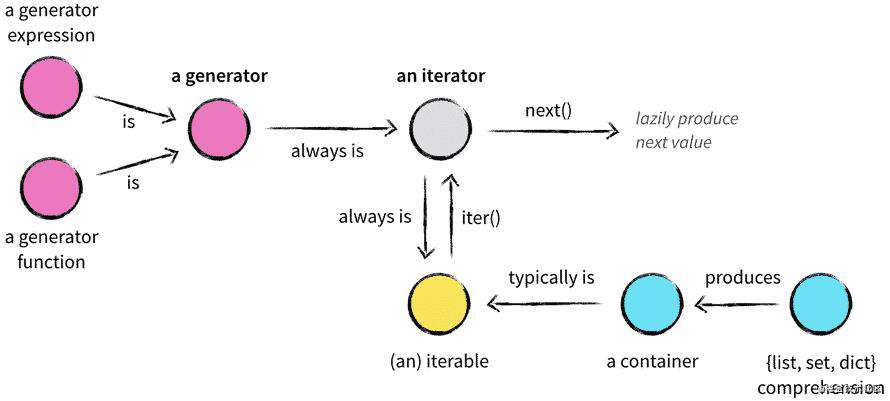
如果一个类实现了 __iter__ 和 __next__ 方法,那么它就是一个迭代器。如果只是实现了 __iter__,并且这个方法返回的是一个迭代器类,那么这个类的实例就只是一个可迭代对象,因为它的迭代细节是交给了另一个类来处理。
像我们经常使用的 list、tuple、set、dict 类型,它们并不是迭代器,只能叫做可迭代对象,它们的迭代细节都是交给了另一个类来处理的。由此我们也得知,一个迭代器一定是一个可迭代对象,但可迭代对象不一定是迭代器。
而生成器可以看做是一个特殊的迭代器,同时它也是一个可迭代对象。使用生成器配合 yield 使用,我们可以实现懒惰计算的功能,同时,我们也可以用非常小的内存,来迭代一个大集合中的数据。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!