有人的地方就有江湖

北京时间5月17日,号称拥有马氏三连鞭、闪电五连鞭的浑元形意太极拳宗师马保国,在山东淄博被一位50岁的民间武术爱好者王庆民30秒KO。如果你还不了解这件震惊中国武林圈的大事,建议你恶补一下这个视频。
我几乎是本能的去b站看了看,播放量已经达到了一个恐怖的境地
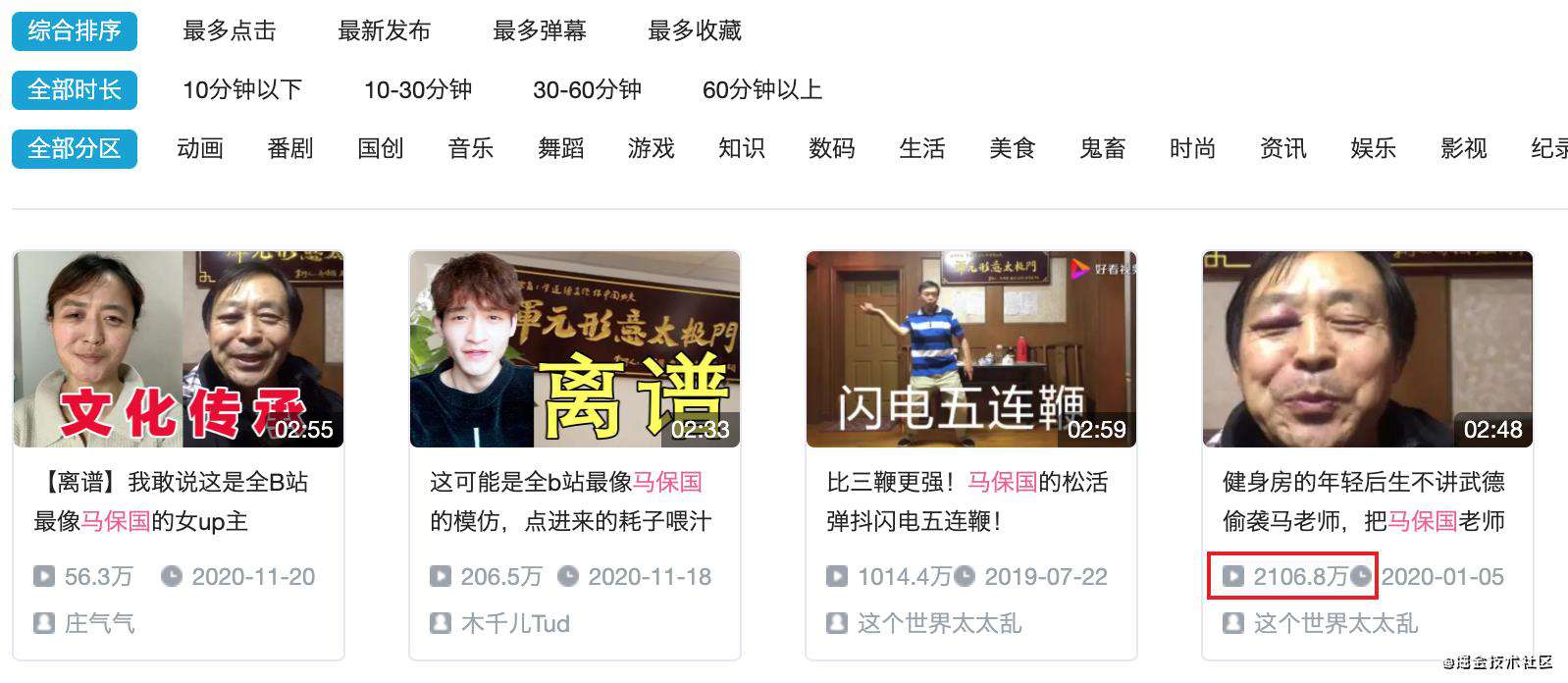

1. 先用jsoup把弹幕爬下来
依赖
<!-- 爬虫相关Jar包依赖 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.10-FINAL</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
代码
package com.example.jm.jmm.util.jsoup;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Description:
* @Param: 爬取b站弹幕
* @Return:
* @Author: Jiangsy
* @Date: 2020/11/20
**/
public class BiliUtil {
public static void main(String[] args) throws Exception{
//视频号
String av = "BV1HJ411L7DP";
String url = "https://api.bilibili.com/x/player/pagelist?bvid="+av+"&jsonp=jsonp";
String result = HttpClientUtil.doGet(url);
//获取cid
String cid = JSONObject.parseObject(result).getJSONArray("data").getJSONObject(0).getString("cid");
System.out.println("cid:{}"+cid);
//获取弹幕打印到文件中
getContent(cid);
}
/**
* @Description:获取弹幕内容
* @Param: [cid]
* @Return: void
* @Author: Jiangsy
* @Date: 2020/11/20
**/
public static void getContent(String cid) throws Exception{
CloseableHttpClient closeableHttpClient = HttpClients.createDefault() ;
HttpGet httpGet1 = new HttpGet("http://comment.bilibili.com/"+cid+".xml");
CloseableHttpResponse httpResponse1 = closeableHttpClient.execute(httpGet1) ;
String en = EntityUtils.toString(httpResponse1.getEntity(), "UTF-8");
String c = "\">(.*?)<" ;
Pattern a = Pattern.compile(c);
Matcher m = a.matcher(en);
File file = new File("/project/11.txt");
if(file.exists()){
file.delete();
}
OutputStream fos=new FileOutputStream("/project/11.txt");
while(m.find()){
String speak = m.group().replace("\">","") ;
speak = speak.replace("<","") ;
System.out.println(speak);
String str=speak;
str+="";
fos.write(str.getBytes());
}
}
}
python的WordCloud生成词云
import jieba
from matplotlib import pyplot as plt
from wordcloud import WordCloud
from PIL import Image
import numpy as np
path = r'ciyun.png'
font = r'/System/Library/Fonts/Hiragino Sans GB.ttc'
text = open('/project/11.txt', 'r', encoding='utf-8').read()
cut = jieba.cut(text) #分词
string = ' '.join(cut)
print(len(string))
img = Image.open('ciyun/22.png') #打开图片
img_array = np.array(img) #将图片装换为数组
stopword=['小米'] #设置停止词,也就是你不想显示的词,这里这个词是我前期处理没处理好,你可以删掉他看看他的作用
wc = WordCloud(
background_color='white',
width=1000,
height=800,
mask=img_array,
font_path=font,
stopwords=stopword
)
wc.generate_from_text(string)#绘制图片
plt.imshow(wc)
plt.axis('off')
plt.figure()
plt.show() #显示图片
wc.to_file('new.png') #保存图片
效果图

the end
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!