当我们下载了需要学习的资料时,发现每篇都是一个独立的章节用起来很不方便,这时候我们可以用Python把它们合并,接下来就一起看看操作方法吧。
一、文件图
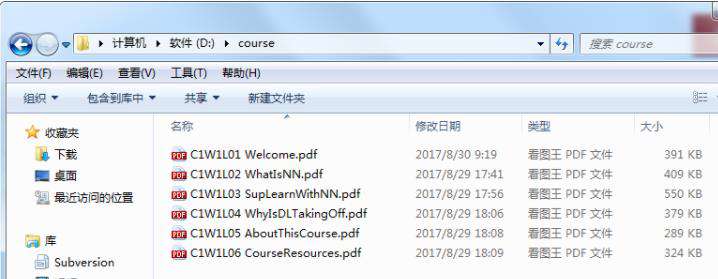
二、合并效果
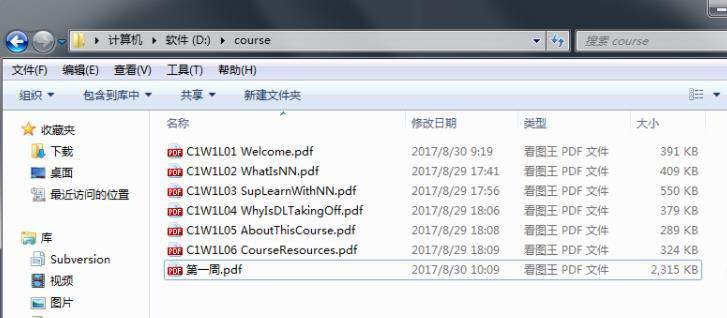
三、python代码
# -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('utf-8') import os import os.path from pyPdf import PdfFileReader,PdfFileWriter import time time1=time.time() # 使用os模块walk函数,搜索出某目录下的全部pdf文件 ######################获取同一个文件夹下的所有PDF文件名####################### def getFileName(filepath): file_list = [] for root,dirs,files in os.walk(filepath): for filespath in files: # print(os.path.join(root,filespath)) file_list.append(os.path.join(root,filespath)) return file_list ##########################合并同一个文件夹下所有PDF文件######################## def MergePDF(filepath,outfile): output=PdfFileWriter() outputPages=0 pdf_fileName=getFileName(filepath) for each in pdf_fileName: print each # 读取源pdf文件 input = PdfFileReader(file(each, "rb")) # 如果pdf文件已经加密,必须首先解密才能使用pyPdf if input.isEncrypted == True: input.decrypt("map") # 获得源pdf文件中页面总数 pageCount = input.getNumPages() outputPages += pageCount print pageCount # 分别将page添加到输出output中 for iPage in range(0, pageCount): output.addPage(input.getPage(iPage)) print "All Pages Number:"+str(outputPages) # 最后写pdf文件 outputStream=file(filepath+outfile,"wb") output.write(outputStream) outputStream.close() print "finished" if __name__ == '__main__': file_dir = r'D:/course/' out=u"第一周.pdf" MergePDF(file_dir,out) time2 = time.time() print u'总共耗时:' + str(time2 - time1) + 's'
"D:\Program Files\Python27\python.exe" D:/PycharmProjects/learn2017/合并多个PDF文件.py D:/course/C1W1L01 Welcome.pdf 3 D:/course/C1W1L02 WhatIsNN.pdf 4 D:/course/C1W1L03 SupLearnWithNN.pdf 4 D:/course/C1W1L04 WhyIsDLTakingOff.pdf 3 D:/course/C1W1L05 AboutThisCourse.pdf 3 D:/course/C1W1L06 CourseResources.pdf 3 All Pages Number:20 finished 总共耗时:0.128000020981s Process finished with exit code 0
合并好的pdf是不是方便查阅了呢~更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!